实验目的
使用kNN构造手写数字识别系统,这里只识别0-9,并且需要识别的数字以及使用图像处理软件处理过了。
实验过程
准备数据:将图像转换为测试向量
数据集分为训练集和测试集,分别包含大约2000个和900个例子,样例如下所示:
这里需要将图像转换为向量。每张图像都是3232像素的,所以我们用numpy建立一个11024的数组来存储向量信息。1
2
3
4
5
6
7
8def img2vec(filename):
returnVec = np.zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVec[0,32*i+j] = int(lineStr[j])
return returnVec
建立数据集
训练集和测试集分别放在两个文件夹中,我们需要将所有的图像都转化为向量,并提取分类标签。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21def setDataSet(trainpath,testpath):
trainFile = os.listdir(trainpath)
train_num = len(trainFile)
trainLabel = []
trainData = np.zeros((train_num,1024))
for i in range(train_num):
number = trainFile[i].split('_')[0]
trainLabel.append(int(number))
trainVec = img2vec('digits/trainingDigits/'+trainFile[i])
trainData[i,:] = trainVec
testFile = os.listdir(testpath)
test_num = len(testFile)
testLabel = []
testData = np.zeros((test_num,1024))
for j in range(test_num):
number = testFile[j].split('_')[0]
testLabel.append(int(number))
testVec = img2vec('digits/testDigits/'+testFile[j])
testData[j,:] = testVec
return trainData,trainLabel,testData,testLabel
最后会生成trainData,trainLabel,testData,testLabel四项数组
kNN分类器
即实现kNN分类算法。由于这里我的数据形式都是数组,所以该分类器只考虑了数组形式的输入,但不同形式的数据,总的思想还是一样的。1
2
3
4
5
6
7
8
9
10
11def classify0(inX,dataSet,label,k):
size_dataSet = dataSet.shape[0]
sqDistance = ((inX - dataSet) ** 2).sum(1)
distance = sqDistance ** 0.5
sortedDistance = distance.argsort()
ClassCount = {}
for i in range(k):
voteILabel = label[sortedDistance[i]]
ClassCount[voteILabel] = ClassCount.get(voteILabel,0) + 1
result = sorted(ClassCount.items(),key = operator.itemgetter(1),reverse = True)
return result[0][0]
简单的说就是输入的向量和训练集中每条样本的每个特征作欧式距离计算,取前k个距离最近的分类标签,最后在这k个标签中取出现次数最多的标签作为最后的输出分类。
测试算法
将测试集作为输入,观察预测结果与实际结果是否一致,计算错误率。1
2
3
4
5
6
7
8
9def handwritingClassTest(trainData,trainLabel,testData,testLabel):
total_test = len(testData)
errorCount = 0
for i in range(total_test):
classResult = classify0(testData[i],trainData,trainLabel,3)
print('预测结果是:{0};实际结果是:{1}'.format(classResult,testLabel[i]))
if classResult != testLabel[i]:
errorCount += 1
print('错误率是:{0}'.format(errorCount/total_test))
实验结果
完整代码见digits.py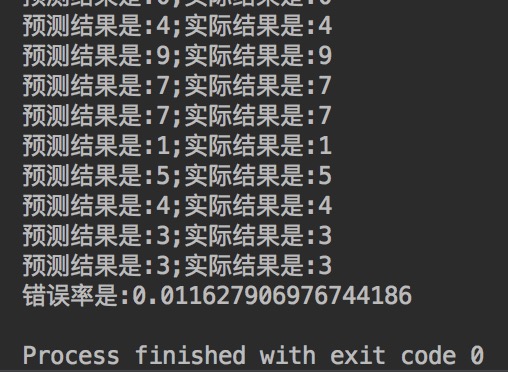
可以看到错误率是1.2%。不过,在实际使用中,该算法的效率并不高,因为算法需要对每个测试向量做2000次距离计算,每个距离包括了1024个维度浮点运算,一共要执行900次,计算开销有点大。
用Sklearn实现手写数字识别
Sklearn是机器学习领域当中最知名的python模块之一。sklearn包含了很多机器学习的方式:Classification 分类、Regression 回归、Clustering 非监督分类、Dimensionality reduction 数据降维、Model Selection 模型选择、Preprocessing 数据与处理等。
使用Sklearn,可以很方便的实现手写数字识别。这里我们调用sklearn.neighbours.KNeighboursClassifier,其具体参数说明如下:
- n_neighbours:默认为5,也就是kNN的k值
- weights:可以是uniform、distance或是用户自己定义的函数,默认是uniform。uniform是均等的权重,就说所有的邻近点的权重都是相等的。distance是不均等的权重,距离近的点比距离远的点的影响大。用户自定义的函数,接收距离的数组,返回一组维数相同的权重。
- algorithm:默认auto(快速k近邻搜索算法),也可以是brute(蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时),kd_tree(构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高),ball tree(克服kd树高纬失效而发明,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。)
- leaf_size:默认30,这个是构造的kd树和ball树的大小。这个值的设置会影响树构建的速度和搜索速度,同样也影响着存储树所需的内存大小。需要根据问题的性质选择最优的大小。
- metric:用于距离度量,默认度量是minkowski,也就是p=2的欧氏距离(欧几里德度量)
- p:距离度量公式,默认为2,也就是欧式距离;2表示曼哈顿距离
- n_jobs:并行处理设置,默认为1,-1表示CPU的所有cores都用于并行工作。
sklearn实现手写数字识别
其他数据处理以及数据集分割部分与前文一致,唯一的区别在于训练以及预测时采用的是库里的模型:1
2
3
4
5
6
7
8
9
10
11
12
13
14def handwritingClassTest(trainData,trainLabel,testData,testLabel):
neigh = KNN(n_neighbors=3,algorithm='auto') # 构建KNN分类器
neigh.fit(trainData,trainLabel)# 拟合模型
errorCount = 0 # 统计错误数量
num_test = len(testData)
for i in range(num_test):
result = neigh.predict([testData[i]])[0]
print('预测结果是:{0};实际结果是:{1}'.format(result,testLabel[i]))
if result != testLabel[i]:
errorCount += 1
print('错误率是:{0}'.format(errorCount/num_test))
执行后,结果如下: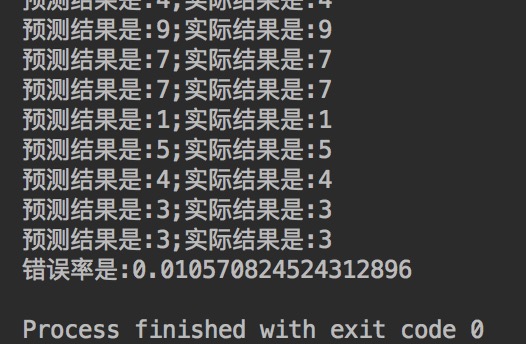
错误率为1.06%,较之前的结果提高一点点。
如果修改n_neighbors algorithm的值,结果会出现细微变化。
一点说明
自己写的kNN见digits.py
调用库写的见digits_sklearn.py
一般来说,直接调用库的效率会更高一点.