实验目的
本实验的目的是利用关键词搜索相关的微信公众号文章标题、公众号、链接等内容并保存到本地。
爬取的来源是搜狗微信搜索平台, 是搜狗在2014年6月9日推出的一款针对微信公众平台而设立的,支持搜索微信公众号和微信文章,可以通过关键词搜索相关的微信公众号,或者是微信公众号推送的文章,我们利用该网站来爬取相关的公众号文章。
实验环境
Chrome+ChromeDriver
python3
主要用到selenium、request、pyquery库等
步骤分析
搜狗对微信公众号平台上的文章和公众号进行了一个整合,可以通过改变关键词来进行相关文章的搜索。这里以搜索“python”为例,将URL中多余的参数进行删减,只留下相关参数,最后得到的链接为:http://weixin.sogou.com/weixin?type=2&query=python: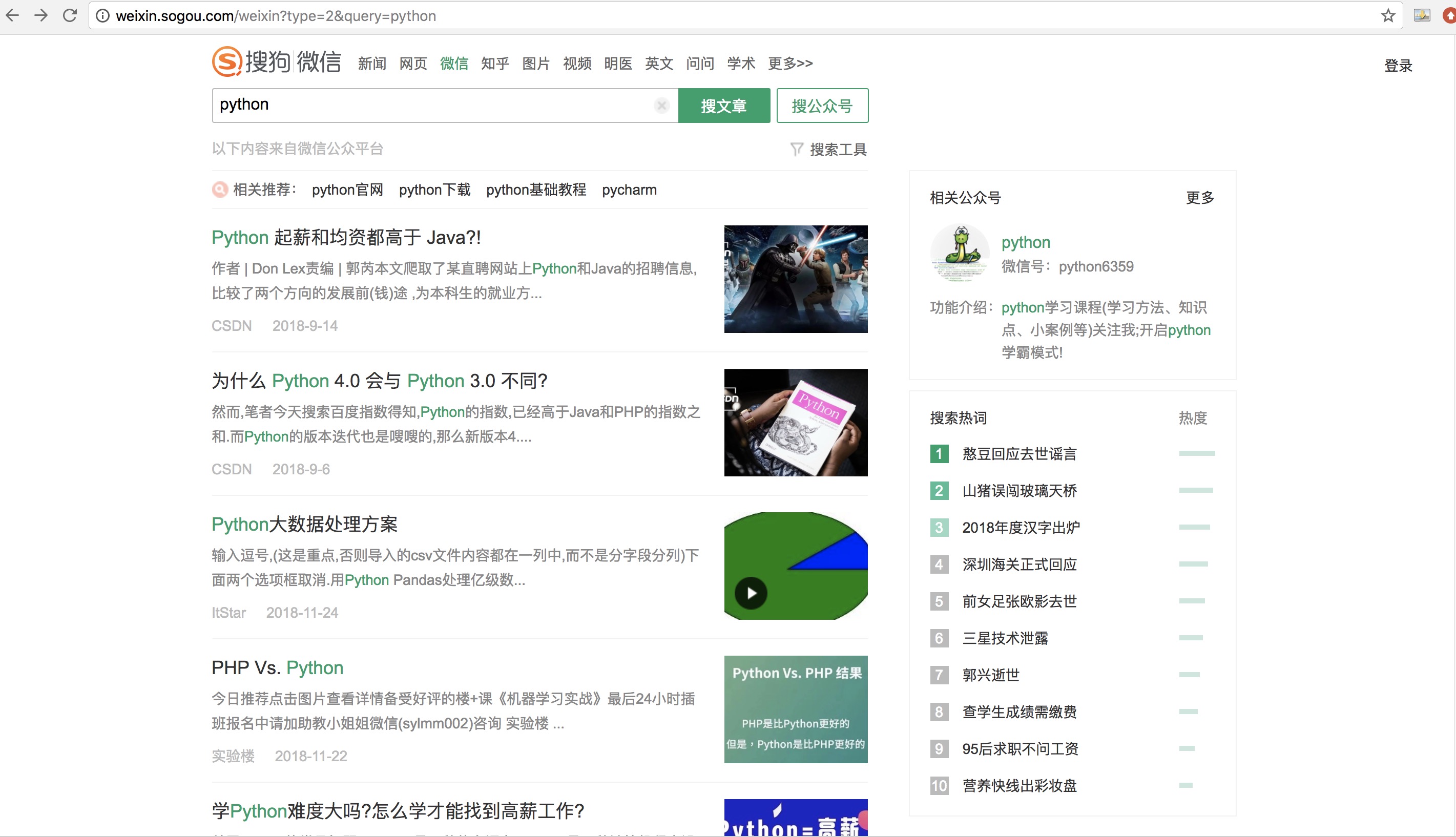
type=2表示搜索微信文章,query是搜索的关键词。
另外,如果多关键词搜索,URL的query参数由+链接,如搜索“python php”:http://weixin.sogou.com/weixin?type=2&query=python+php 。
下拉页面,可以看到页面导航栏: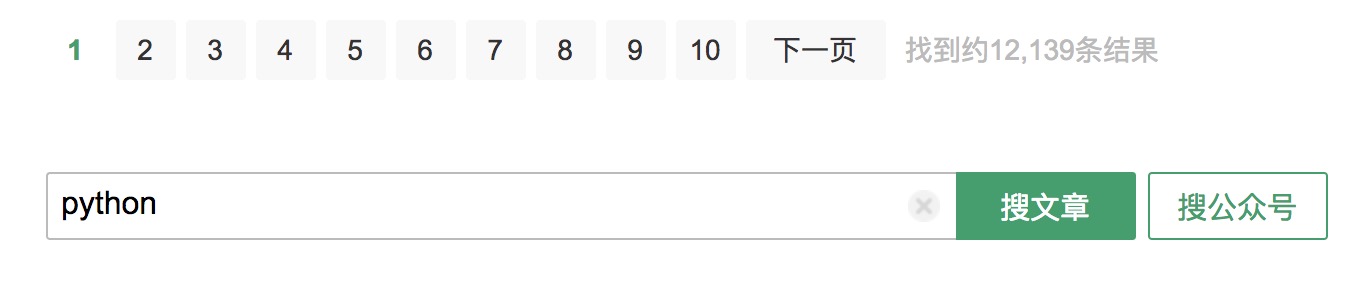
由于没有登录账号,所以只能看到10页的内容;如果登录账号,则可以看到100页的内容,所以在爬取的时候,我们要先微信扫码登录账户。
进行翻页操作后,URL多了一个page的参数。
如果页面连续刷新的速度过快,该站点就会启动反爬虫机制,弹出验证码,为了避免这种情况,我们有三种解决方案:
1.识别验证码进行IP解封
2.使用代理池,切换IP
3.引入time模块,每爬取一页休息几秒
后两种方法可以按照实际情况选用。
实验过程
获取cookie
由于该网站必须要登录才能查看完整的信息,所以要先模拟登录,获取cookies,方便后面的请求。1
2
3
4
5
6
7
8
9
10
11
12def get_cookies():
driver = webdriver.Chrome()
driver.get("http://weixin.sogou.com/")
driver.find_element_by_xpath('//*[@id="loginBtn"]').click()
time.sleep(10)
cookies = driver.get_cookies()
cookie = {}
for items in cookies:
cookie[items.get('name')] = items.get('value')
return cookie
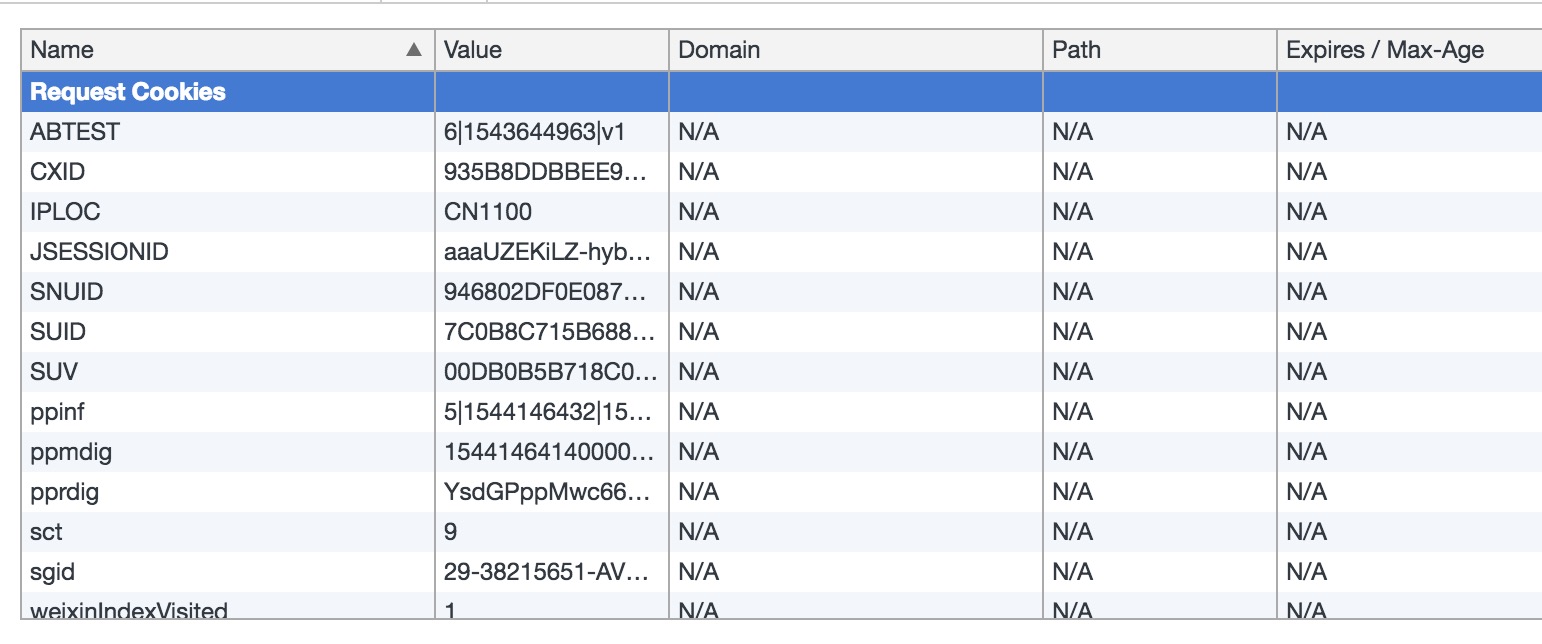
后续使用request时,都需要带上爬取下来的cookies,实现登录效果。
实现翻页
观察每一页的URL:
https://weixin.sogou.com/weixin?type=2&query=python&page=1
https://weixin.sogou.com/weixin?type=2&query=python&page=2
https://weixin.sogou.com/weixin?type=2&query=python&page=3
可以看到只需要改变page参数就可以实现翻页
由于搜索关键词的不同,总页数也是不一样的,最大为100页,所以我们需要获取该关键词的总页数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22def parse_url(url,cookie):
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'weixin.sogou.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0'
}
response = requests.get(url,headers = header,cookies=cookie)
if response.status_code == 200:
response = response.text
return response
def total_page():
url = 'https://weixin.sogou.com/weixin?type=2&query=' + keyword + '&page=100'
response = parse_url(url,cookie)
doc = pq(response)
print(doc)
totalPage = doc.find('#pagebar_container.p-fy span').text()
return totalPage
解析页面
每一页的内容都包含在news-list中: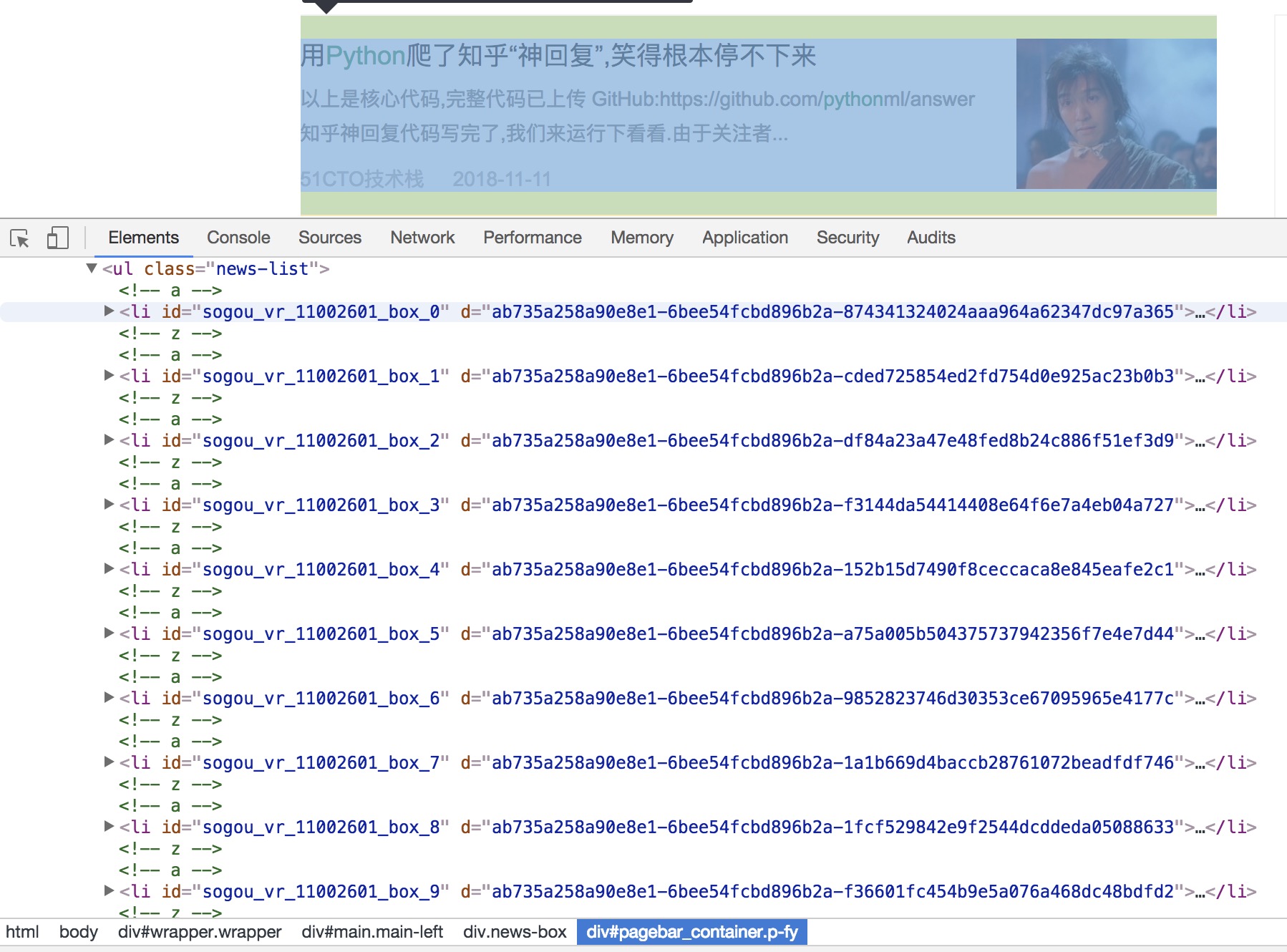
观察每条数据,发现都包含了文章标题、图片、正文链接、日期、公众号等信息: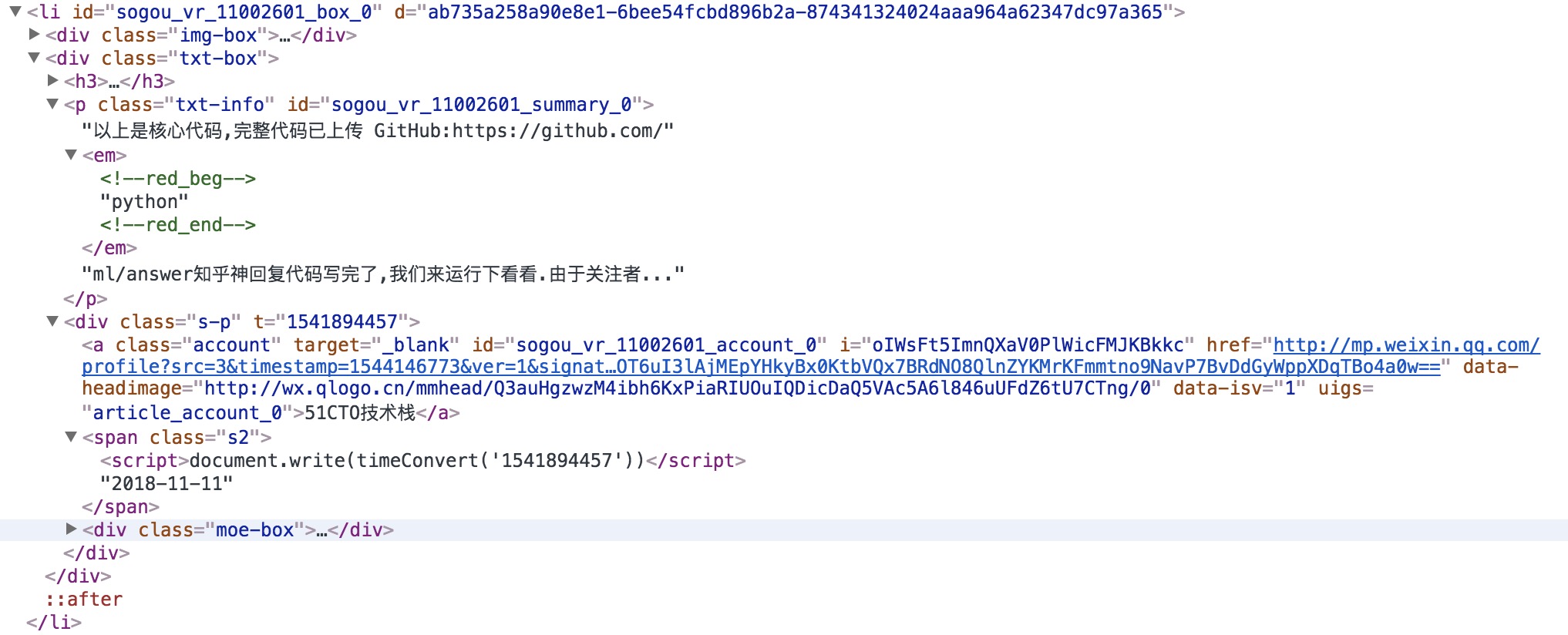
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def parse_page(page):
url = 'https://weixin.sogou.com/weixin?type=2&query=' + keyword + '&page=' + str(page)
response = parse_url(url,cookie)
doc = pq(response)
items = doc.find('.news-list li').items()
for item in items:
source = item.find('.s-p .account').text()
href = item.find('.txt-box h3 a').attr('href')
response = requests.get(href).text
doc1 = pq(response)
title = doc1.find('.rich_media_title').text()
yield {
'title':title,
'source':source,
'url':href
}
存储结果
将爬取的结果存储到csv表中,方便查询:1
2
3
4
5
6
7
8
9
10def save_to_csv(info):
file_dir = "{0}".format(os.getcwd())
if not os.path.isdir(file_dir):
os.makedirs(file_dir)
path = os.path.join(file_dir,keyword+".csv")
dataframe = pd.DataFrame(info)
# 设置保存的列顺序,否则pandas会重新排序
columns = ['title','source','url']
dataframe.to_csv(path,mode='a',encoding="utf_8_sig",columns=columns)
return path
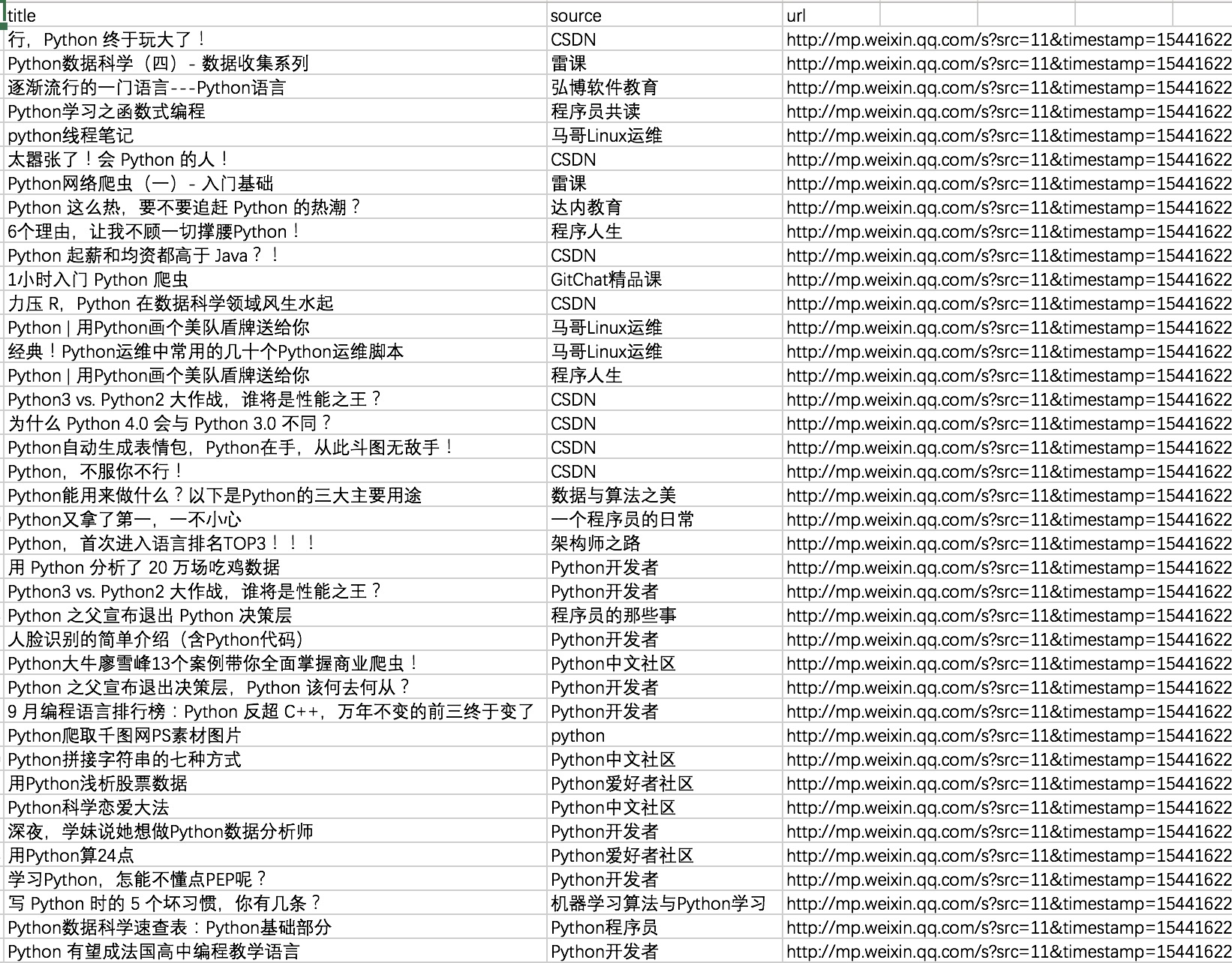
实验结果与说明
完整代码见WeChat1.py
以查询python关键词为例,运行代码:1
python WeChat1.py python
得到结果如下: