实验目的
本次实验的目的是爬取QQ空间的说说,并进行分词制作词云图,词云图的效果如下图所示:
实验环境
Chrome V70
ChromeDriver V2.43
python3
主要用到selenium、pyquery、jieba、wordcloud、matplotlib等python库
步骤分析
我们爬取的是空间说说的页面,其URL为:https://user.qzone.qq.com/{qq_number}/311, 首先就是解决登录问题,在页面源码中找到登录模块: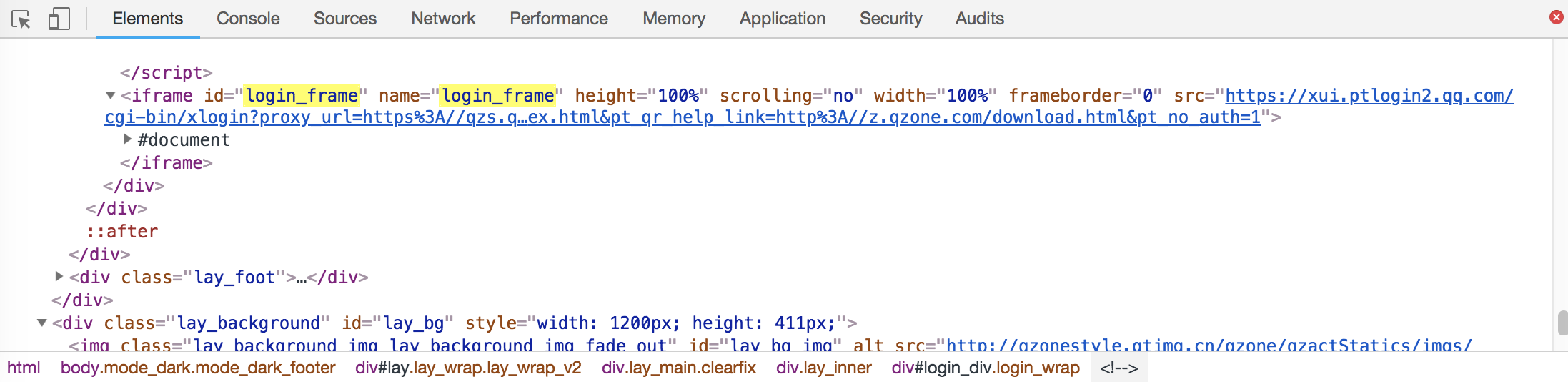
可以发现,login模块位于iframe元素块中,所以必须要先跳转到这一内敛框架,才能使用selenium对该部分进行解析与相应操作,可以用switch_to.frame()方法进行框架跳转。登录操作可以用selenium+chromedriver实现账号密码自动化登录,也可以手动扫码登录。下图是账号密码登录的页面源码,如果选择自动登录,只要找到输入框的位置,使用send_keys()输入账号密码与click()方法点击按钮就可以实现登录操作。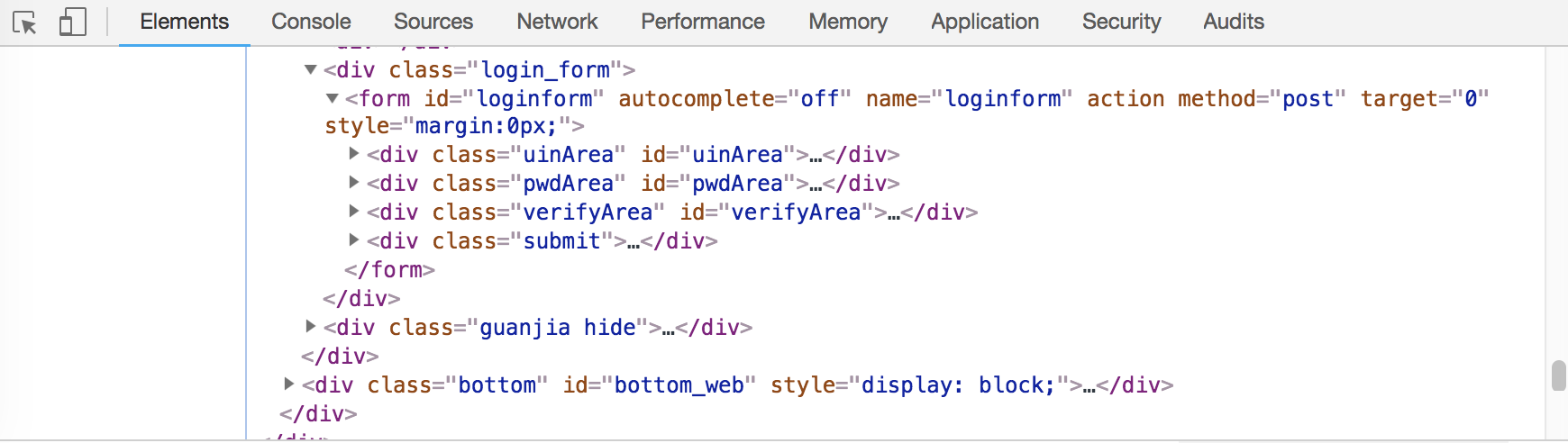
登陆成功后,就进入到“全部说说”界面,可以发现,该页面是动态加载的,需要不断下拉页面,使当前页完全加载完毕,才会显示出页码导航栏:
如果出现多页情况,我们就要对页面进行翻页操作。有两种操作,一种是直接点击下一页,另一种是在输入框输入页码点击跳转按钮进行翻页。对于前者,很容易出现“下一页”按钮点击不到的情况,并且如果由于网络等问题,翻页中止,还得增加一个记录点进行记录,操作较为不便;所以我们这里选择的是后者。
可以看到我们要提取的信息位于class=’msgList’的位置,每一页最多显示20条说说: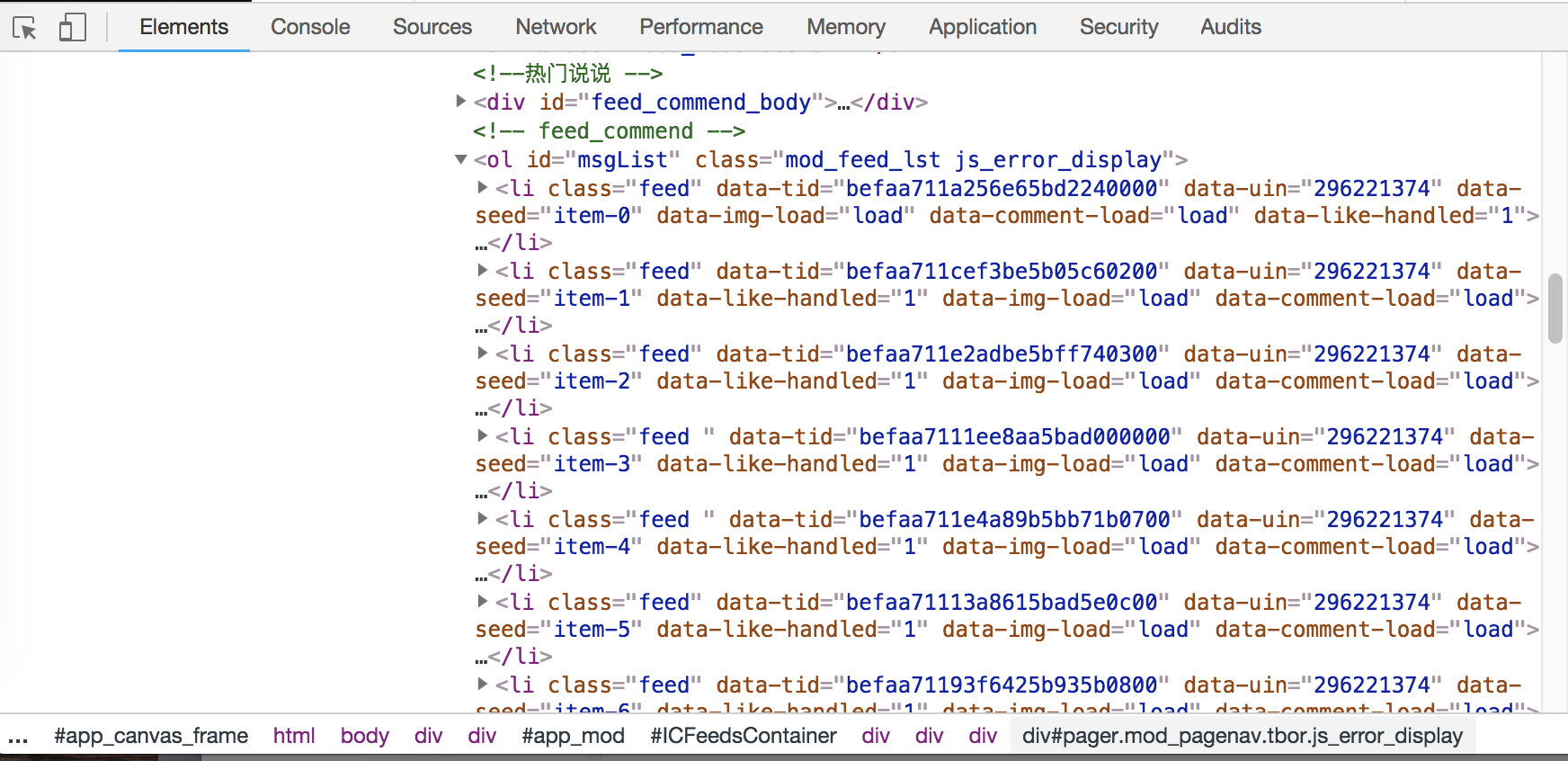
爬取的内容包括说说内容以及发布时间和客户端来源,这些内容利用pyquery对页面进行解析即可。
实验过程
登录功能
第一种是利用selenium打开浏览器后,手动扫码登录。1
2
3
4
5
6url = 'https://user.qzone.qq.com/'+qq_number+'/311'
browser = webdriver.Chrome()
browser.get(url)
wait = WebDriverWait(browser,200)
# username = 'username'
# pwd = 'password'
也可以设置自动登录。1
2
3
4
5
6
7
8
9
10
11
12username = 'username'
pwd = 'password'
browser.switch_to.frame('login_frame')
button = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#switcher_plogin.link')))
button.click()
user_input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#uinArea>div>input#u.inputstyle')))
pwd_input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#pwdArea>div>input#p.inputstyle.password')))
submit_button = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#loginform>div>a>input#login_button.btn')))
user_input.send_keys(username)
pwd_input.send_keys(pwd)
submit_button.click()
对于自动登录,第一步switch_to.frame()非常关键,否则浏览器无法解析到该iframe中的内容,selenium无法对其中的内容进行相应的操作。
用WebDriverWait确认输入账号密码的位置加载完毕后,模拟浏览器,用send_keys()方法输入账号密码,然后用click()方法点击提交按钮进行登录。
下拉页面
下拉页面执行javascript,这里只需要将页面拉到底部即可。1
2
3browser.switch_to.default_content()
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(5)
值得注意的是,这里用了switch_to.default_content()方法,是因为前面登录模块位于iframe中,现在我们要对iframe之外的元素进行操作,就必须切换出去,否则selenium是解析不到这些元素的。
获取总页数
通过分析可以知道,只有超过20条说说,才会产生分页效果。如果是不足20条说说,则会隐藏分页导航栏: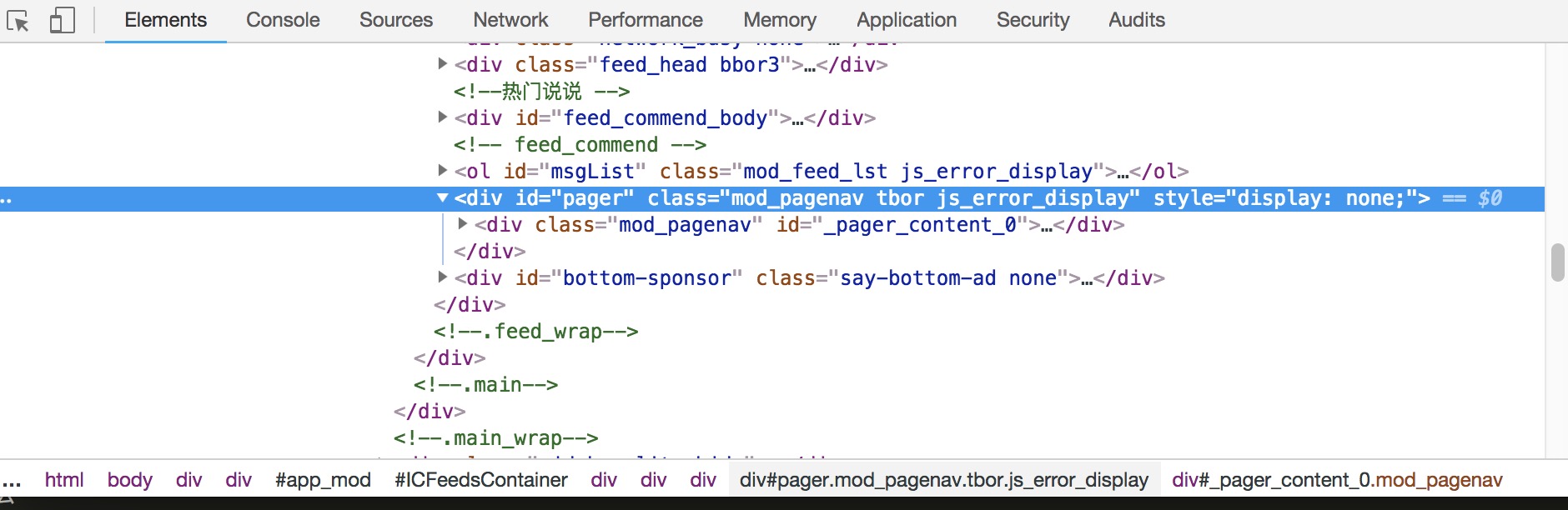
可以看到,没有分页的时候,会多了一个元素叫style=“display: none;”,所以要对这两种情况进行分类。1
2
3
4
5
6
7
8
9
10
11browser.switch_to.frame('app_canvas_frame')
doc = pq(browser.page_source)
if doc.find('div#pager.mod_pagenav.tbor.js_error_display').attr('style') == 'display: none;':
total_page=1
else:
total_page = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#pager>#_pager_content_0>p>#pager_last_0>span'))).text # 最后一页
total_page = int(total_page)
print('Total page:',total_page)
browser.switch_to.default_content()
由于分页功能也是位于‘app_canvas_frame’的子框架中,所以要切换进去。获取到页面源码后,判断是否存在style这个元素,如果存在,则默认页数为1;否则,提取页数信息,获得总页数。
最后,切换回原来的框架,方便后续操作。
页面跳转
一开始我们选择的是点击“下一页”进行页面跳转,但是会遇到模拟点击的时候页面没有完全加载完毕从而点击的位置不在“下一页”的情况,也有可能遇到点击“下一页”页面没有跳转的问题,所以这里选择在输入框输入要跳转的页码进行翻页。1
2
3
4CSS_sel = '#pager>#_pager_content_'+str(next_num)+'>p>span>input#pager_go_'+str(next_num)+'.textinput'
next_input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,CSS_sel)))
next_input.send_keys(int(next_num+1))
next_input.send_keys(Keys.ENTER)
输入完页码后,引用Keys模块,模拟键盘敲击ENTER键,完成页面的跳转。
注意,实际编写代码的时候,要考虑总页数为1的情况,也要根据实际情况判断是否应该切换frame。
提取信息
我们要提取的信息位于class=‘msgList’中,提取的格式如下:1
2
3{'time': ('2018年9月26日 9:59',), 'source': 'iPhone (4G)', 'content': '从上班的第一个小时开始倒计时下班 实在是太困了 上班真难啊'}
{'time': ('2018年9月14日 20:26',), 'source': 'iPhone 8 Plus (4G)', 'content': '谁能想到 九月 还有蚊子'}
{'time': ('2018年8月1日 20:31',), 'source': 'iPhone 8 Plus', 'content': '真的6'}
用字典记录每一条说说的内容,包括发表时间、客户端来源、说说内容,然后保存到本地文件中。1
2
3
4
5
6
7
8
9
10browser.switch_to.frame('app_canvas_frame')
doc = pq(browser.page_source)
items = doc('#msgList li.feed').items()
for item in items:
shuoshuo_dic = {}
shuoshuo_dic['time'] = item.find('div.box.bgr3>div.ft>div.info>.c_tx3>.c_tx.c_tx3.goDetail').attr('title'),
shuoshuo_dic['source'] = item.find('div.box.bgr3>div.ft>div.info>.c_tx3>.custom-tail').attr('title')
shuoshuo_dic['content'] = item.find('.content').text()
with open('qzone.txt','a+') as f:
f.write(str(shuoshuo_dic)+'\n')
制作词云
制作词云图主要用到三个库:wordcloud(生成词云)、matplotlib(生成词云图片)、jieba(显示中文)。
提取完所有的信息后,我们得到了txt文件,每条说说以字典形式记录在内,出于制作词云图的需要,我们只需要说说正文内容,所以再对txt文件做一次加工,提取出所有的key=content的value,进行词云图的制作。1
2
3
4
5f = open('QZone.txt').readlines()
for each in f:
content = eval(each)
with open('content.txt','a+') as f:
f.write(content['content']+'\n')
利用jieba分词制作词云,主要就是先进行分词,然后设置词云,最后画图。具体的参数解释可以参考完整代码里的注释部分。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24#生成词云
def create_word_cloud(filename):
text= open("{}.txt".format(filename)).read()
# 结巴分词
wordlist = jieba.cut(text, cut_all=True)
wl = " ".join(wordlist)
# 设置词云
wc = WordCloud(
background_color="white",
max_words=2000,
font_path=r'/System/Library/Fonts/STHeiti Light.ttc',
height= 1200,
width= 1600,
max_font_size=100,
random_state=30,
)
myword = wc.generate(wl) # 生成词云
# 展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()
wc.to_file('WordCloud.png')
如果想要更新分词字典,比如设置一些人名、流行语等不被分割,可以用jieba.add_word()方法增加。
完整代码
爬取说说:完整代码见QZone.py
生成词云:完整代码见QZone_cloud.py
实验结果与说明
爬取说说:1
python QZone.py QQ_number

会生成QZone.txt的文件。
生成词云图:1
python QZone_cloud.py
效果如开头所示。
最后说明,有时候自动登录如果爬取的次数多了,会遇到填写验证码,可以自行加入验证码模块,也可以直接选择扫码登录;如果想要爬取好友的说说,只需要在运行的时候输入好友的QQ号,用自己的账号密码登录即可,但要确保有空间访问权限。