k-近邻算法概述
工作原理
存在一个样本数据集合(称作训练样本集),并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。当输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般只选取样本集中前k个最相似的数据。最后,选择这k个数据中出现次数最多的分类,作为新数据的分类。
简单实现
1 | import numpy as np |
注意,这里dataSet和labels都是用pandas进行处理过的。dataSet为DataFrame类型,labels是series类型。
文字描述简单归纳为三步:特征距离计算、选择距离最小的k个点、按类别出现的次数排序
这里以欧式距离作为计算标准
实战:使用kNN改进约会网站配对效果
准备数据:从文本文件中解析数据
约会对象的数据文本为datingTestSet2.txt
数据格式如下图: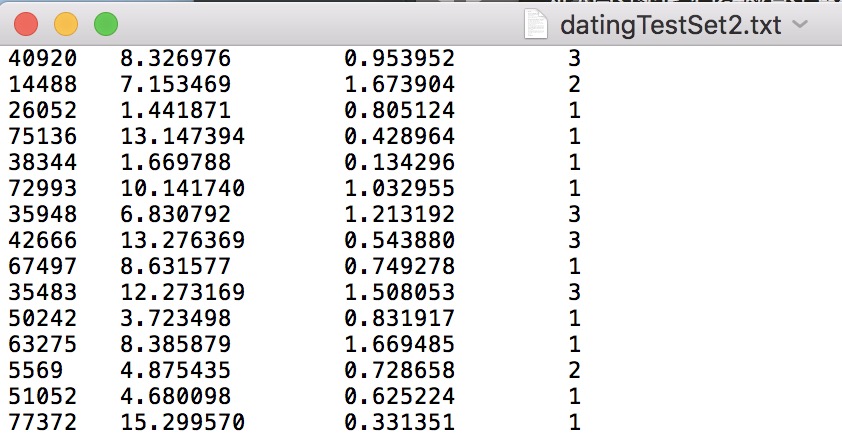
一共有1000条数据,每条数据包含三种特征:每年获得的飞行常客里程数、玩视频游戏所耗时间的百分比、每周消费的冰淇淋公升数
将这些特征数据输入到分类器之前,需要先将其格式处理成分类器能接受的格式。1
2
3
4
5
6
7
8
9
10
11
12
13
14'''
函数说明:打开并解析文件,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力
Parameters:
filename - 文件名
Returns:
datingData - 特征矩阵
datingLabel - 分类Label向量
'''
def file2matrix(filename):
data = pd.read_csv(filename,names = ['airplane','game','ice-cream','label'],sep = '\t')
datingData = data[['airplane','game','ice-cream']]
datingLabel = data[['label']].replace({'largeDoses':3,'smallDoses':2,'didntLike':1})
return datingData,datingLabel
这里我们用pandas来处理文本数据,将原始数据加上特征名与标签名,前三列为特征值,最后一列为分类标签,并将分类标签中的文字转换成1、2、3这样的类别。
最后会形成两个DataFrame格式的数据,分别代表样本和标签
分析数据:使用Matplotlib创建散点图
蓝点表示不喜欢、黄点表示一般魅力、红点表示极具魅力1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53'''
函数说明:可视化数据
Parameters:
datingData - 特征矩阵
datingLabel - 分类Label
Returns:
无
'''
def showfigure(datingData,datingLabel):
font_path=r'/System/Library/Fonts/STHeiti Light.ttc'
Font1 = FontProperties(fname=font_path,size=9)
Font2 = FontProperties(fname=font_path,size=7)
# 蓝点表示不喜欢、黄点表示一般魅力、红点表示极具魅力
labelColor = []
for i in datingLabel['label']:
if i == 1:
labelColor.append('blue')
if i == 2:
labelColor.append('yellow')
if i == 3:
labelColor.append('red')
print(labelColor)
fig = plt.figure()
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 每年获得的飞行常客里程数&玩视频游戏所耗时间的百分比
ax1 = fig.add_subplot(221)
ax1.scatter(datingData.iloc[:,0],datingData.iloc[:,1],c=labelColor,s=15,alpha=0.5) # 散点大小15 透明度0.5
ax1.set_title(u'每年获得的飞行常客里程数&玩视频游戏所耗时间的百分比',FontProperties=Font1)
ax1.set_xlabel(u'每年获得的飞行常客里程数',FontProperties=Font2)
ax1.set_ylabel(u'玩视频游戏所耗时间的百分比',FontProperties=Font2)
# 每年获得的飞行常客里程数&每周消耗的冰淇淋公升数
ax2 = fig.add_subplot(222)
ax2.scatter(datingData.iloc[:,0],datingData.iloc[:,2],c=labelColor,s=15,alpha=0.5)
ax2.set_title(u'每年获得的飞行常客里程数&每周消耗的冰淇淋公升数', FontProperties=Font1)
ax2.set_xlabel(u'每年获得的飞行常客里程数', FontProperties=Font2)
ax2.set_ylabel(u'每周消耗的冰淇淋公升数', FontProperties=Font2)
# 玩视频游戏所耗时间的百分比&每周消耗的冰淇淋公升数
ax3 = fig.add_subplot(223)
ax3.scatter(datingData.iloc[:,1],datingData.iloc[:,2],c=labelColor,s=15,alpha=0.5)
ax3.set_title(u'玩视频游戏所耗时间的百分比&每周消耗的冰淇淋公升数', FontProperties=Font1)
ax3.set_xlabel(u'玩视频游戏所耗时间的百分比', FontProperties=Font2)
ax3.set_ylabel(u'每周消耗的冰淇淋公升数', FontProperties=Font2)
# 设置图例
didntLike = mlines.Line2D([], [], color='blue', marker='.',markersize=6, label='didntLike')
smallDoses = mlines.Line2D([], [], color='yellow', marker='.',markersize=6, label='smallDoses')
largeDoses = mlines.Line2D([], [], color='red', marker='.',markersize=6, label='largeDoses')
# 添加图例
ax1.legend(handles=[didntLike, smallDoses, largeDoses])
ax2.legend(handles=[didntLike, smallDoses, largeDoses])
ax3.legend(handles=[didntLike, smallDoses, largeDoses])
plt.show()

准备数据:归一化数值
这里认为三种特征的重要性是一样的,所以应当对每列特征的数值进行归一化处理
可以用min-max标准化方法:
也可以用Z-score标准化方法(标准正态分布):
其中$\mu$为所有样本数据的均值、$\theta$为所有样本数据的标准差。
所以这里需要编写一个函数将特征值进行归一化处理:1
2
3
4
5
6
7
8
9
10
11
12
13
14'''
函数说明:对数据进行归一化
Parameters:
dataSet - 特征矩阵
Returns:
data_norm - 归一化后的特征矩阵
'''
def autoNorm(dataSet):
data_norm = (dataSet-dataSet.min())/(dataSet.max()-dataSet.min())
data_norm = (dataSet - dataSet.mean()) / (dataSet.std())
return data_norm
#data_norm = (dataSet - dataSet.mean()) / (dataSet.std())
用min-max方法处理后的结果如下: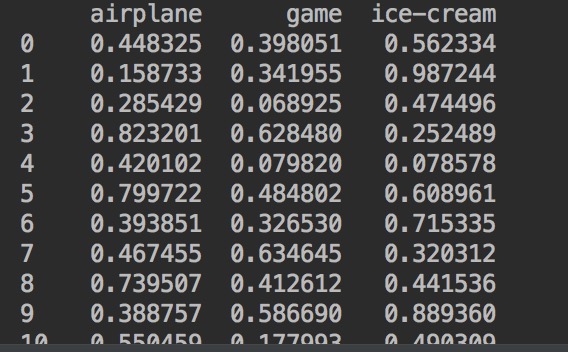
测试算法:作为完整程序验证分类器
可以用错误率来检测分类器的性能。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29'''
函数说明:分类器测试函数
Parameters:
无
Returns:
errorCount - 错误率
'''
def datingClassTest():
hoRatio = 0.1 # 10%作为测试集,90%作为训练集
filename = 'datingTestSet.txt'
datingData, datingLabel = file2pandas(filename)
norm_data = autoNorm(datingData)
total_data = norm_data.shape[0]
num_test_data = int(total_data * hoRatio)
test_data = pd.DataFrame(norm_data[0:num_test_data])
train_data = pd.DataFrame(norm_data[num_test_data:]).reset_index(drop=True)
train_label = pd.Series(datingLabel[num_test_data:]).reset_index(drop=True)
errorCount = 0 #分类错误计数
for i in range(num_test_data):
classifyResult = classify0(test_data[i:i+1].values[0],train_data,train_label,3)
print('预测结果:{0};实际结果:{1}'.format(classifyResult,datingLabel.values[i]))
if classifyResult != datingLabel.values[i]:
errorCount += 1
print('错误率是:{0}'.format(errorCount/num_test_data))
取前10%作为测试集,后90%作为训练集,预测结果以及错误率如下:
可以看到该分类器处理约会数据的错误率为5%,该结果还不错。通过改变k值或是训练测试的比例,错误率会发生变化。
使用算法:构建完整可用系统
完成了kNN分类器的测试后,错误率可观,所以可以将此分类器投入使用。输入用户的三个特征后,由分类器进行判断,是否可以进行下一步约会。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28'''
函数说明:通过输入一个人的三维特征,进行分类输出
Parameters:
无
Returns:
无
'''
def classifyPerson():
resultList = ['不喜欢','一般魅力','极具魅力']
airmiles = float(input('每年获得的飞行常客里程数:'))
games = float(input('玩视频游戏所耗时间的百分比:'))
ice = float(input('每周消耗的冰淇淋公升数:'))
filename = 'datingTestSet.txt'
datingData, datingLabel = file2pandas(filename)
norm_data,minVal,maxVal = autoNorm(datingData)
inX = np.array([airmiles,games,ice])
norm_inX = (inX-minVal)/(maxVal-minVal)
item = list(norm_inX.items())
df_data = pd.DataFrame({'0':[item[0][1]],'1':[item[1][1]],'2':[item[2][1]]})
data = df_data.values[0]
result = classify0(data,norm_data,datingLabel,3)
print('这个人可能:{0}'.format(resultList[result-1]))
依次输入10000,10,0.5后,得到的测试结果如下:
得到的结果是一般魅力,说明可能可以进行约会。
一点说明
这里在构造kNN分类器时,规定dataSet和label都是dataframe类型的。
完整代码见kNN_dating.py