实验目的
本次实验的目的是爬取58租房信息,并调用高德地图API,将房源在地图上标记,使得在找房的过程中更直观。
实验环境
python3
主要用到pyquery、requests等库
调用了高德API
爬取分析
本实验以北京市海淀区的房源为例,筛选了价格为2000-3000的房子,其第一页的URL为:https://bj.58.com/haidian/pinpaigongyu/pn/1/?minprice=2000_3000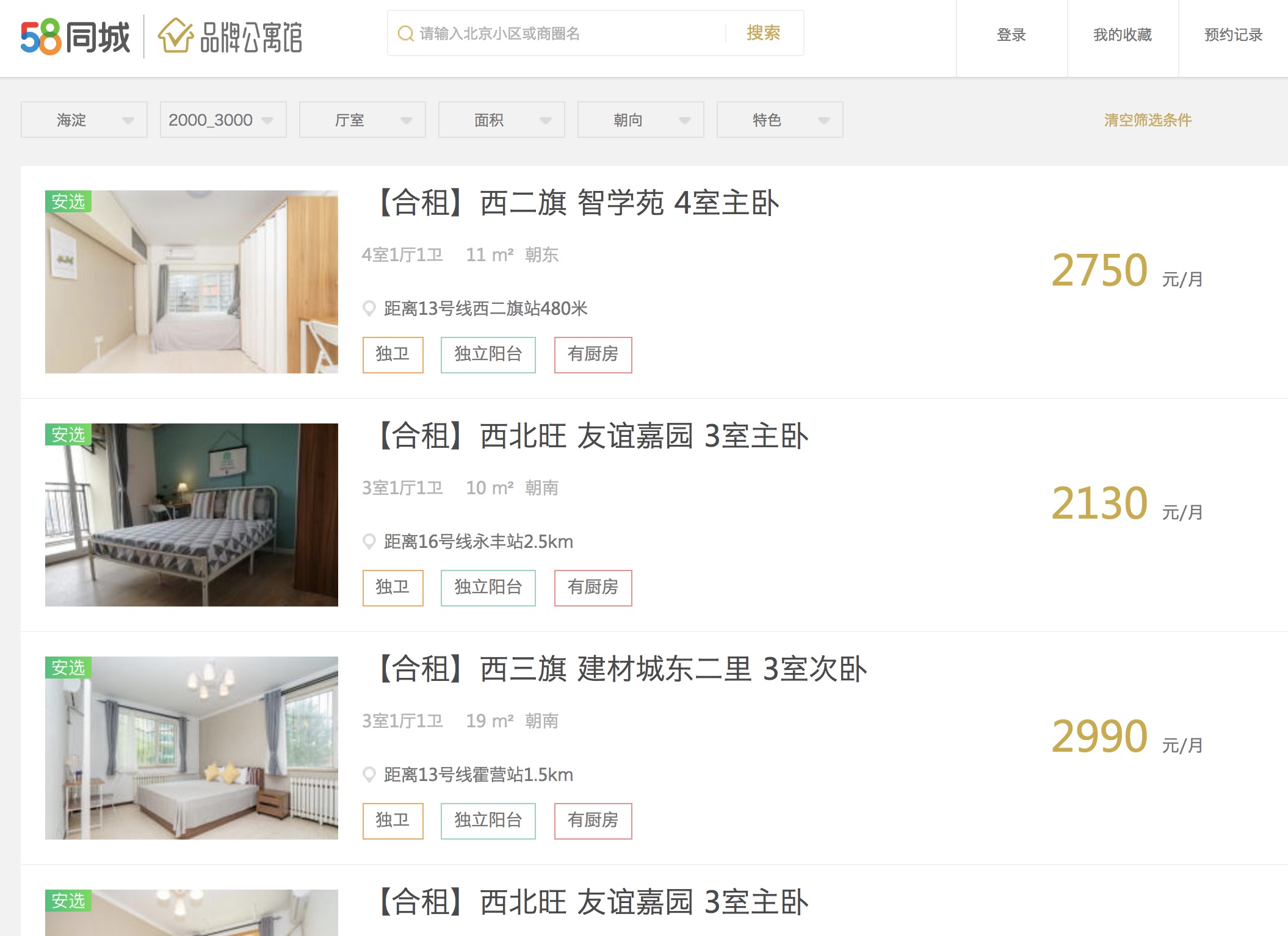
我们要爬取的信息是:房源名称、价格、房间信息、位置,其中位置信息是通过房源标题来获取的。
我们用requests对该网站发起请求,只要修改URL参数,就能实现翻页。但是,通过实践可以发现,如果翻到最后一页(这里一共是121页),继续请求122页,仍然会获取到信息,所以有两种方法可以避免这种情况,一是实验之前自行判断一共有多少页,修改代码;二是通过pyquery解析页面,判断哪一页的class=‘page’处没有出现“下一页”,则当前页为最后一页。
这里选取第二种方法: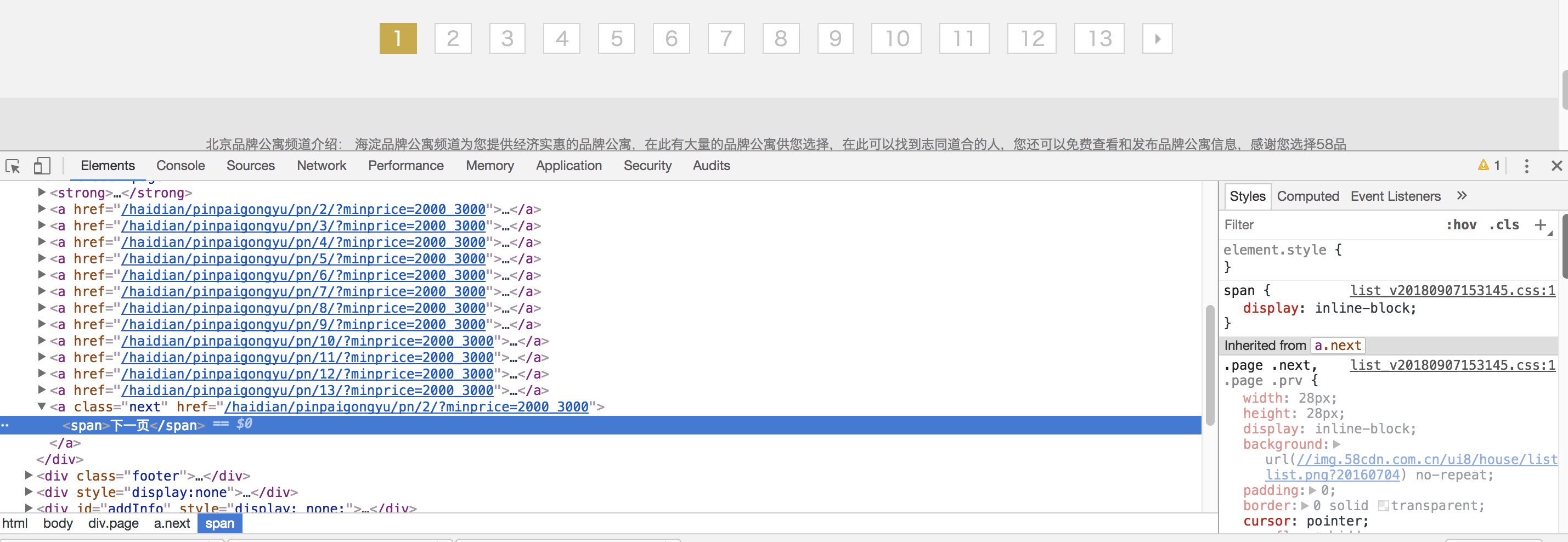
打开开发者工具,可以发现每页显示20条信息:
但是该网站存在反爬机制,可以发现所有的数字都重新编码了,那么本实验的难点就在于将这些乱码的数字反编回正确的值。
实验过程
翻页以及最后一页判断
这里我们采用判断是否存在“下一页”的方法1
2
3if page != 1 and doc.find('.page a').eq(-2).text() != '下一页':
print('All done')
break
数字的处理
这部分是本实验的关键,首先观察页面源码,找到@font-face自定义字体:
可以看到,这里将原本正常的数据隐藏了,而且通过刷新页面可以看到,每次这段被base64加密的数据都不一样,所以要进行动态提取:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16resp = requests.get(url.format(page),headers=random.choice(headers))
if resp:
#提取BASE64加密的数据
base64_str = re.findall('data:application/font-ttf;charset=utf-8;base64,(.*?)\'\) format\(\'truetype\'\)}',resp.text)
#解密并获取对应字体编码的结构
bin_data = base64.b64decode(base64_str[0])
fonts = TTFont(io.BytesIO(bin_data))
bestcmap = fonts.getBestCmap()
#将CMAP的序号变成数字
newmap = {}
for key in bestcmap.keys():
value = int(re.findall(r'(\d+)', bestcmap[key])[0]) - 1
key = hex(key)
newmap[key] = value
print('==========', newmap)
此时,得到的newmap是16进制与数字的对应关系,该关系随着页面的刷新会不断变化。
但我们源码中显示的是类似于“闰龤龤”这样的形式,所以还需要做一次转化,用FontCreatro打开微软雅黑的ttf,获取文字对应的编码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25def getrealValue(newmap,fakevalue):
# 用FontCreatro打开微软雅黑的ttf,获取文字对应的编码
font58 = {
'闰': '0x958f',
'閏': '0x958f',
'鸺': '0x9e3a',
'鵂': '0x9e3a',
'麣': '0x9ea3',
'饩': '0x993c',
'餼': '0x993c',
'鑶': '0x9476',
'龤': '0x9fa4',
'齤': '0x9f64',
'龥': '0x9fa5',
'龒': '0x9f92',
'驋': '0x9a4b'
}
fake_array = [each for each in fakevalue]
length = len(fake_array)
for i in range(0,length):
if fake_array[i] in font58.keys():
fake_array[i] = str(newmap[font58[fake_array[i]]])
realValue = ''.join(fake_array)
return realValue
通过getreakValue(),我们就能得得到真实的数字了。
爬取房源信息
房源信息用pyquery进行解析页面即可得到:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20for each in house_list.items():
# 获取房源链接
house_url = each.find('a').eq(0).attr('href')
# 房源名称
house_name = each.find('.des.strongbox h2').text()
# 房间信息
house_room = each.find('.des.strongbox .room').text()
# 价格
house_price = each.find('.money .strongbox').text()
# 地点信息提取
#house_location = re.findall('\s+(.*?)\s+',house_name)
house = re.findall('】(.*?)\s+(.*?)\s+', house_name)
if not house:
house_location == 'Unknow'
else:
if "公寓" in house[0][0] or "青年社区" in house[0][0]:
house_location = house[0][0]
else:
house_location = house[0][1]
在提取地点信息的时候,我们直接从房源的名称里就可以提取小区的名字,一般来说是存放在中间的,但是有时候有些标题小区名称位于最前列,所以要单独处理。另外,有的房源名称里没有包含小区名字,所以要标记一下。
分别将这些信息进行处理,得到真实值:1
2
3
4
5house_name= getrealValue(newmap,str(house_name))
house_room = getrealValue(newmap,str(house_room))
house_price = getrealValue(newmap,str(house_price))
最后将数据整合成字典的形式,方便后续写入文件,创建一个列表house_data[],将每一页的数据以字典形式存入列表中:1
2
3
4
5
6
7
8house_info = {
'name':house_name,
'location':house_location,
'room':house_room,
'price':house_price,
'url':house_url
}
house_data.append(house_info)
保存成csv
这里还是用pandas进行数据的存储1
2dataframe = pd.DataFrame(house_data)
dataframe.to_csv(path, mode='a', encoding="utf_8_sig", columns=columns)
调用地图API
这里,我们调用高德API,在高德地图上展示爬取的房源信息,而且通过搜索地点,通勤方式选择,可以清楚的看到哪些房源距离目标地点较为方便。
具体的用法可以参考高德地图API给出的demo,也可以看代码注释。
结果与说明
完整代码见58
运行RentHouse.py,爬取房源数据: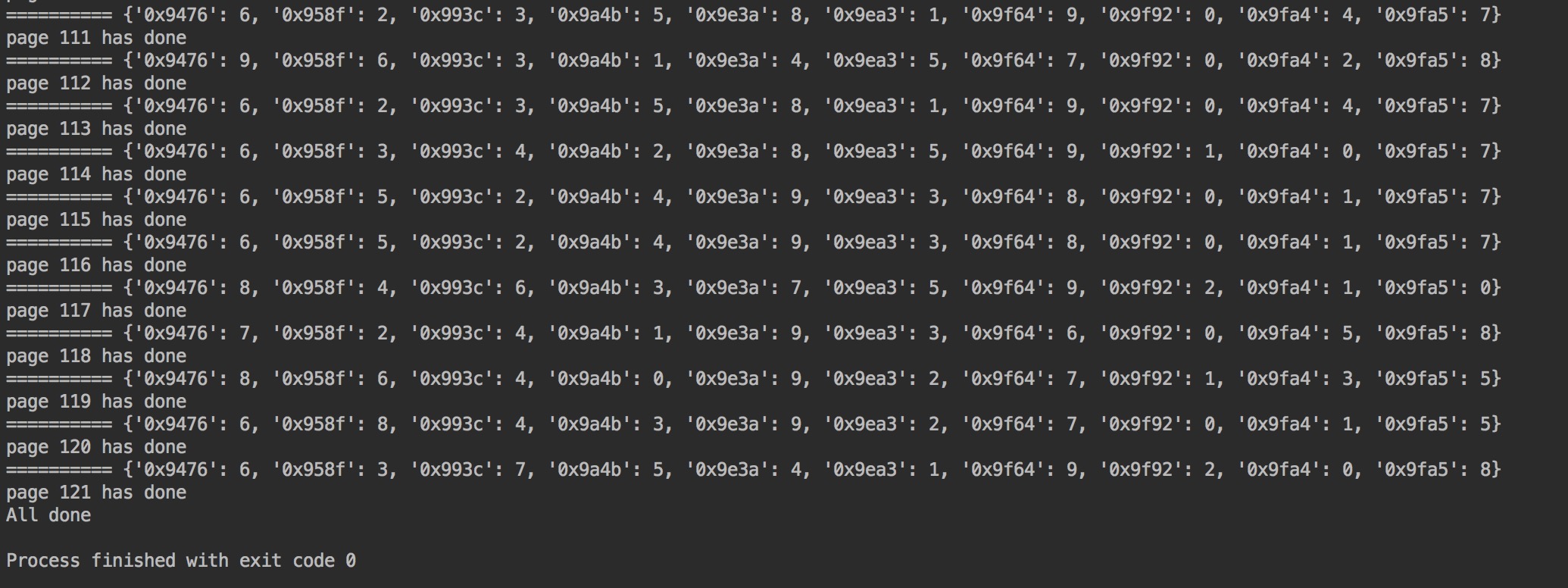
得到BJ_haidian_2000-300.csv
在存放csv和map.index的目录下,开启服务:1
python -m http.server 3000
注意,一定要将这两者放在同一目录下,否则无法加载数据
然后再浏览器中打开:1
localhost:3000
输入目标地点,并导入房源文件后,结果如下: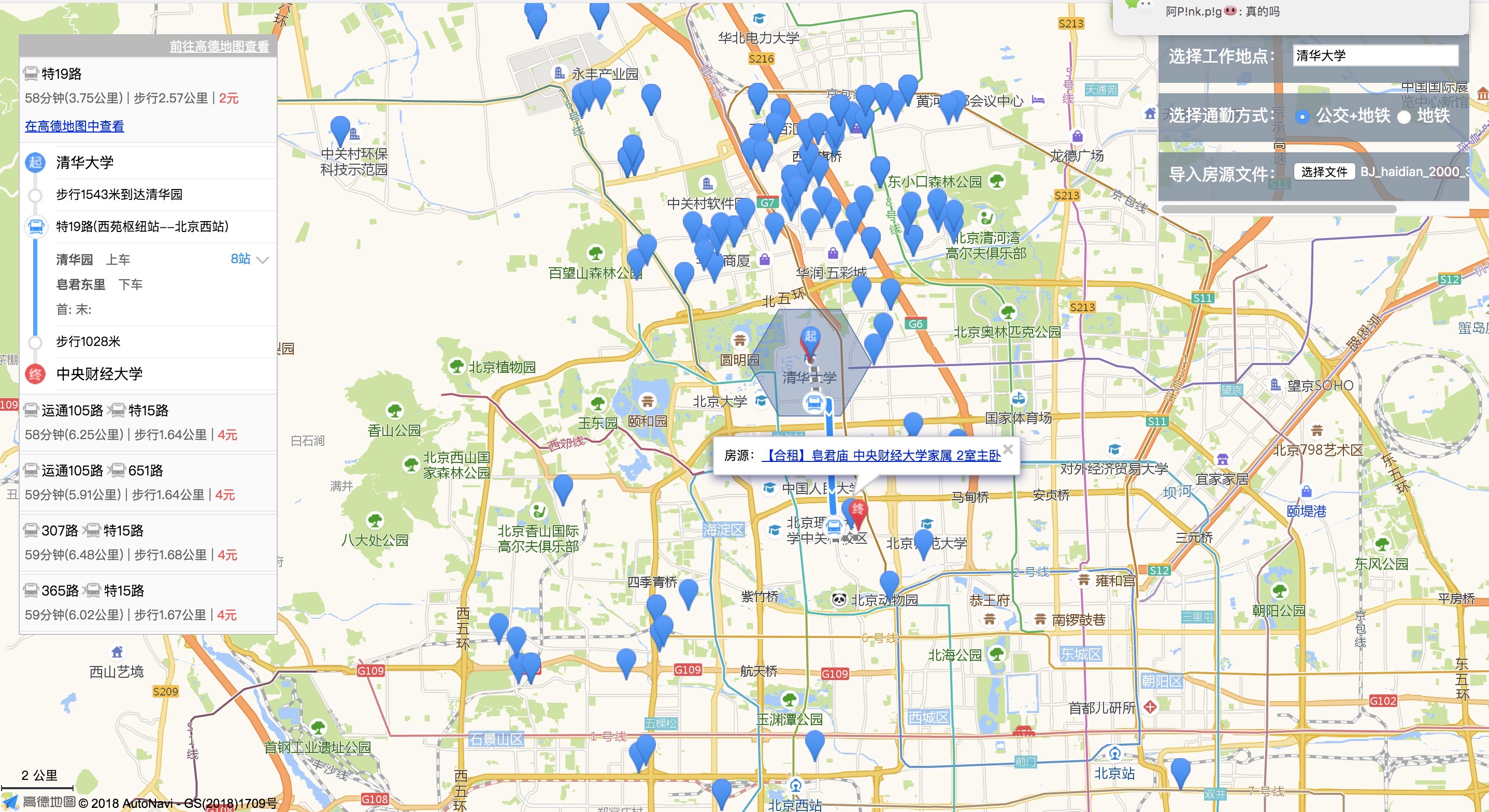
任意点击一处房源,可以显示出交通时间等信息
最后说明:如果想要换一个地区换一个价格进行查询,修改py中的爬取链接,并修改html中的地点坐标即可。