实验目的
在利用爬虫爬取我们想要的信息时,往往会遇到一些反爬虫能力很强的网站,返回状态码403Forbidden或是提醒我们”您的IP访问频率太高”,需要我们输入验证码或是直接封了当前IP。遇到这种情况,使用代理IP是一个不错的选择,利用代理IP发起请求,而不用影响我们的真实IP。所以,搭建一个代理池,存放一些可用的代理IP是利用爬虫的过程中非常有效的一个手段。
实验环境
MongoDB
python3
主要用到requests、pyquery、pymongo库
爬取分析
本实验搭建的代理池,其代理IP都是一些免费的高匿代理,所以会有时效性,需要在使用时进行生命验证并进行更新。
搭建代理池主要分成三个部分:
1.获取代理IP
从一些代理网站抓取免费的高匿代理,代理的形式都是IP+端口。
2.验证可用性
检测代理的可用性。可以设置一个检测链接,最好是爬取哪个网站就用哪个网站进行检测,也可以直接用百度等网站进行测试。
3.存储到数据库
利用mongo数据库,存储抓取下来的可用代理。
实验过程
代理获取
主要从一些免费的代理网站获取代理IP,比如西刺、66代理等网站都可以抓取。
解析代理网站,获取代理ip,这里以西刺为例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def parse_url(url):
headers = [
{'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0'},
{'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'},
{'User-Agent': 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11'},
{'User-Agent': 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)'},
{'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:40.0) Gecko/20100101 Firefox/40.0'},
{'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36'}
]
try:
response = requests.get(url,headers=random.choice(headers))
if response.status_code == 200:
return response.text
except ConnectionError:
print('Error')
观察页面,可以看到有翻页操作,找到相关元素: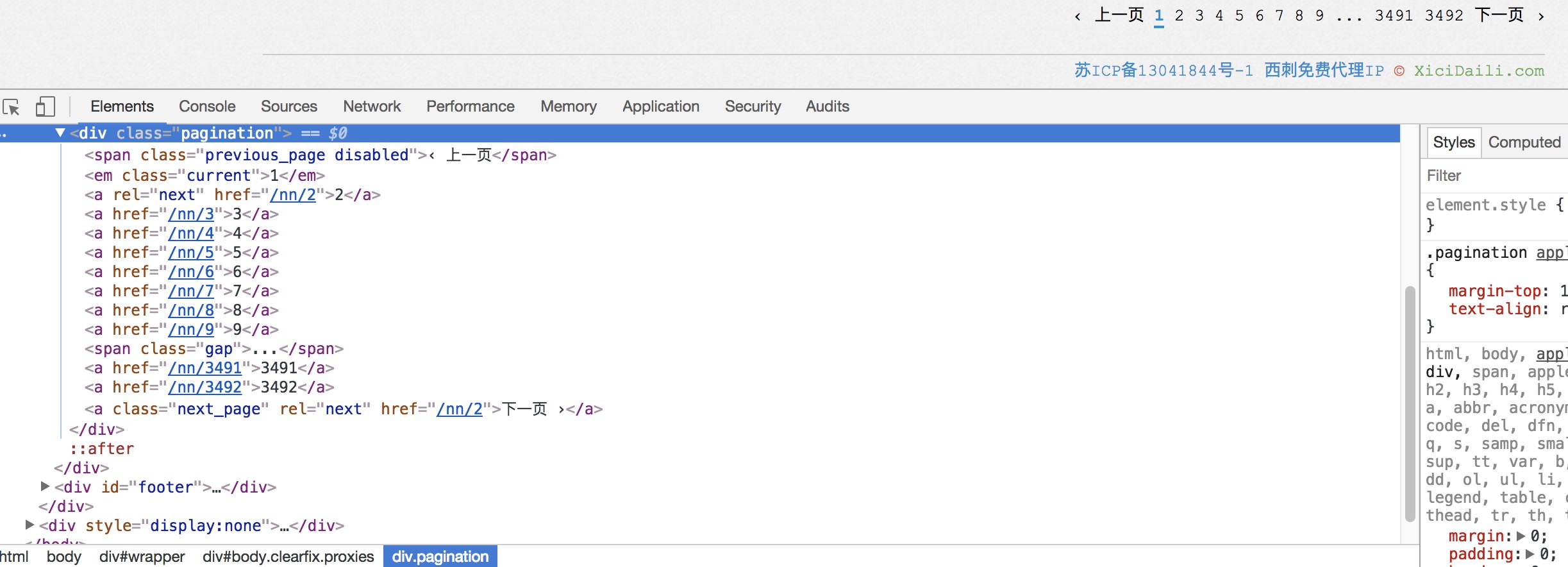
获取总页数,并通过构造URL:’http://www.xicidaili.com/nn/{}'.format(page) 实现翻页。
1 | def proxy_xici(): |
用pyquery解析每一页,在ip_list里提取每一个代理的IP和PORT,写入字典并存进列表里。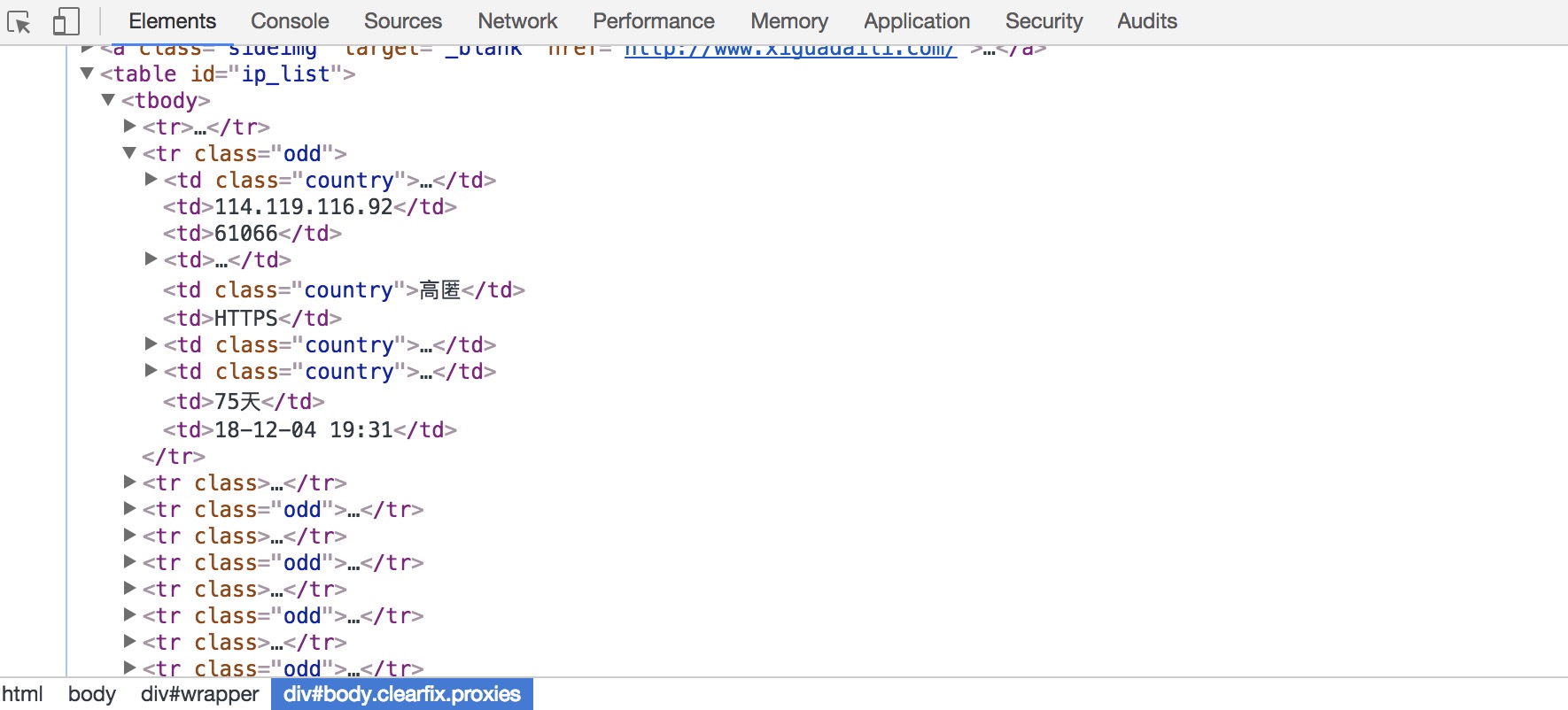
代理验证
抓取到每页的代理IP和端口号后,我们用百度进行验证,如果返回的状态码是200,且间隔时间小于10秒,则认为该代理是有效的:1
2
3
4
5
6
7
8
9def proxy_test(proxy):
try:
resp = requests.get(TEST_URL, proxies={'http': 'http://{0}:{1}'.format(proxy['ip'], proxy['port']),
'https': 'https://{0}:{1}'.format(proxy['ip'], proxy['port'])}, timeout=10)
if resp and resp.status_code == 200:
#collection.insert_one(proxy)
print('Valid proxy', proxy)
except Exception as e:
pass
数据库存储
本实验采用的是mongo数据库,将所有通过验证的代理存储到数据库中:1
2
3
4
5client = MongoClient("localhost",27017)
db = client.proxies
collection = db['Proxy_Port']
collection.insert(proxy)
实验结果与说明
完整代码见ProxyPool.py
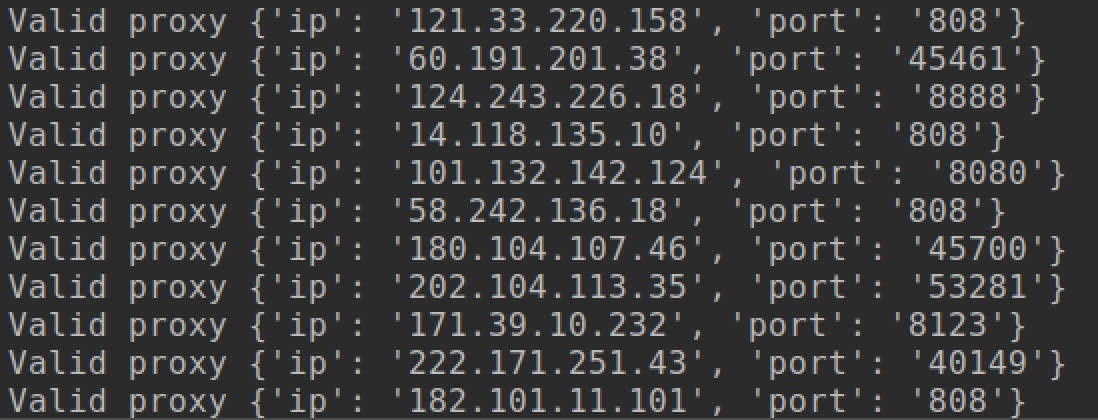
运行完整代码,结果如下:1
python ProxyPool.py
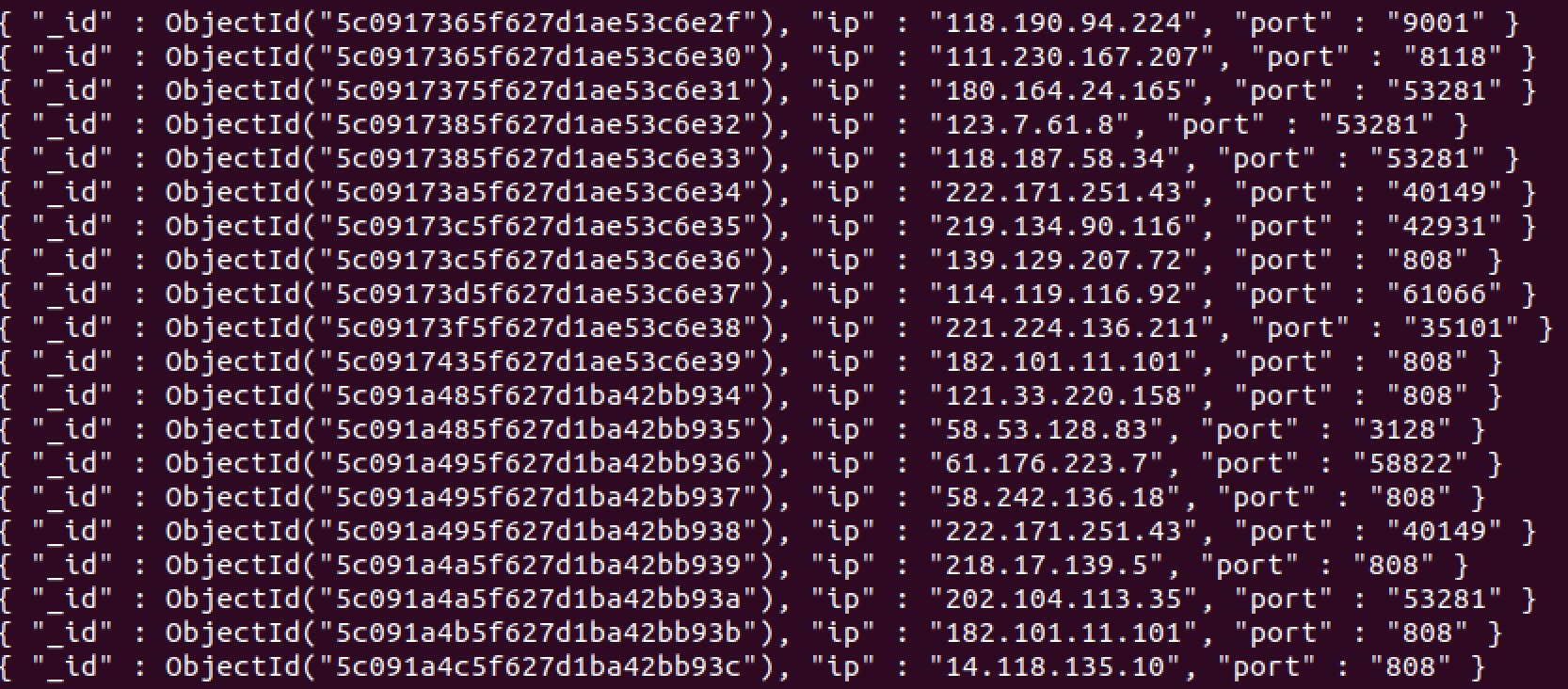
查看proxies数据库里的Proxy_Port表,存放的部分内容如下: