实验目的
本次实验的目的是以北京的Python职位为例,爬取拉勾网相关职位的招聘信息。
实验环境
python3
主要用到requests、pyquery、pandas等库
爬取分析
以北京地区的Python职位为例,其URL为:https://www.lagou.com/jobs/list_Python?city=%E5%8C%97%E4%BA%AC
通过翻页,可以发现URL没有变化,打开开发者工具可以看到,请求是通过POST提交的,数据通过Ajax方式加载。
提交的数据如下所示: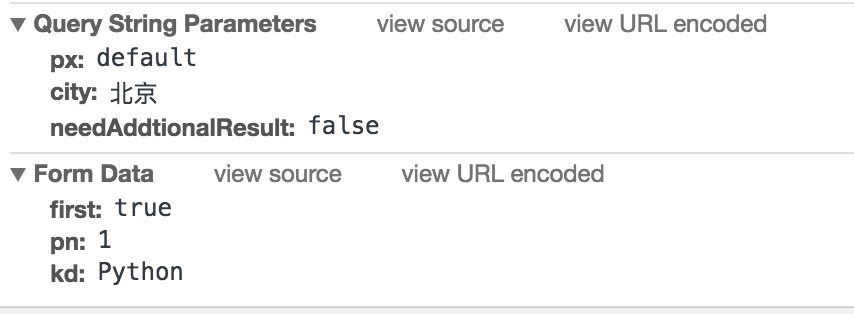
其中,pn代表页数,kd代表关键字
返回的数据格式如下: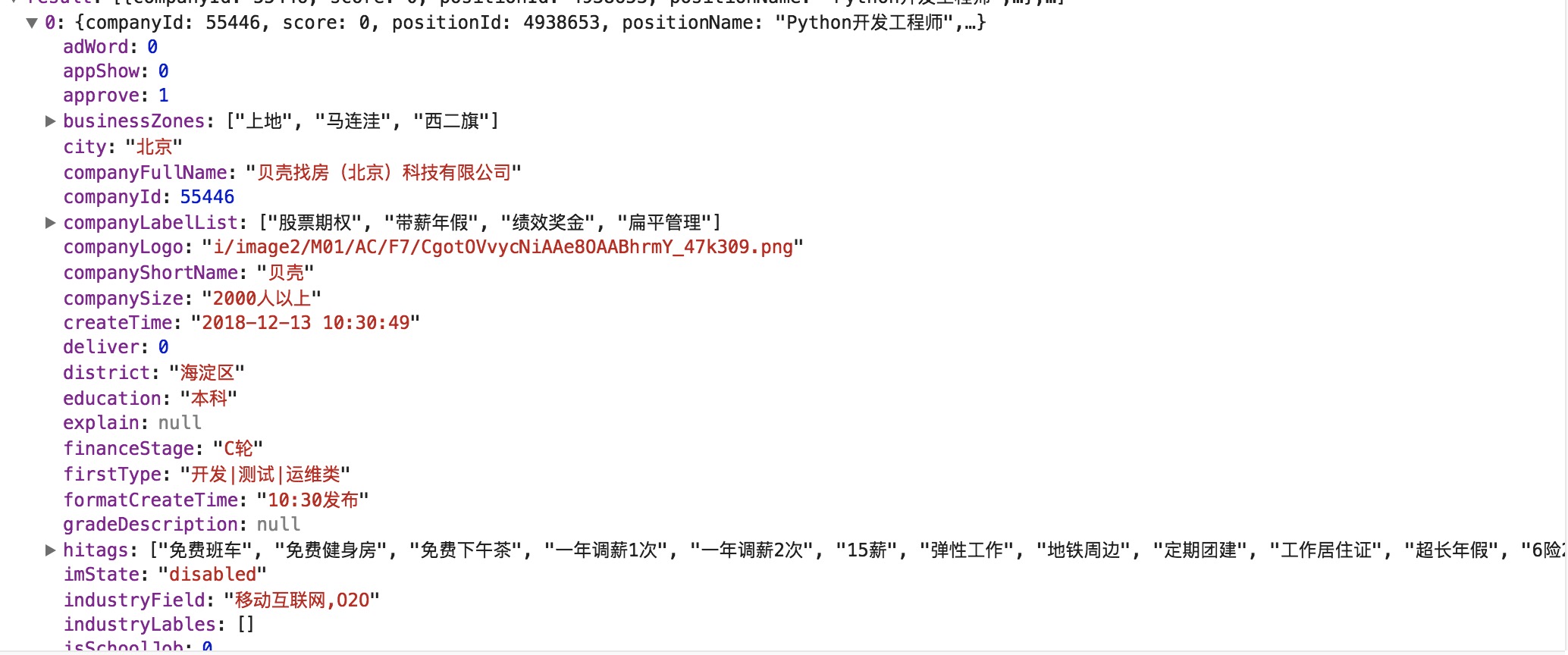
所以,本实验的思路就是构造请求头模拟Ajax请求,从返回的数据里提取需要的信息并保存,翻页的操作就通过post的数据改变pn来完成。
实验过程
发起请求
构造请求头,将要post的数据写进请求头,由于网站的反爬虫机制,所以我们要构造一个完整的请求头,并加上cookie信息1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def get_json_data(city,position,page):
url ='https://www.lagou.com/jobs/positionAjax.json?px=default&city={0}&needAddtionalResult=false'.format(city)
datas = {
'first': 'true',
'pn': page,
'kd': position,
}
cookie = 'write your cookies here'
headers = {'cookie': cookie,
'origin': "https://www.lagou.com",
'x-anit-forge-code': "0",
'accept-encoding': "gzip, deflate, br",
'accept-language': "zh-CN,zh;q=0.8,",
'user-agent': UserAgent().random,
'content-type': "application/x-www-form-urlencoded; charset=UTF-8",
'accept': "application/json, text/javascript, */*; q=0.01",
'referer': "https://www.lagou.com/jobs/list_Pyhon?labelWords=&fromSearch=true&suginput=",
'x-requested-with': "XMLHttpRequest",
'connection': "keep-alive",
'x-anit-forge-token': "None"}
response = requests.post(url,headers=headers,data=datas)
return response.json()
服务器接收到模拟的请求后,会返回json格式的数据
解析json
得到每一页返回的json格式的数据后,从中提取出有用的信息1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41def parse_json(json):
# 状态是成功的再处理
tmp_jobs = []
job_info = json.get('content').get('positionResult').get('result')
for item in job_info:
results = {}
companyShortName = item.get('companyShortName')
companyFullName = item.get('companyFullName')
companySize = item.get('companySize')
positionName = item.get('positionName')
workYear = item.get('workYear')
salary = item.get('salary')
industryField = item.get('industryField')
financeStage = item.get('financeStage')
createTime = item.get('createTime')
education = item.get('education')
district = item.get('district')
positionId = item.get('positionId')
jobNature = item.get('jobNature')
positionAdvantage = item.get('positionAdvantage')
positionUrl = 'https://www.lagou.com/jobs/' + str(positionId) + '.html'
results = {
'公司名称':companyFullName,
'职位名称':positionName,
'工作年限':workYear,
'薪资范围':salary,
'行业':industryField,
'融资情况':financeStage,
'公司简称':companyShortName,
'公司规模':companySize,
'发布时间':createTime,
'学历要求':education,
'地区':district,
'工作性质':jobNature,
'职位优势':positionAdvantage,
'职位ID':positionId,
'职位链接':positionUrl
}
tmp_jobs.append(results)
return tmp_jobs
将每一条招聘信息存成字典格式,并存入列表中,方便后续写入文件。
得到总页数
因为要进行翻页,我们必须知道总共的页数是多少,可以先进行第一页请求的发起,在返回的数据中查看总的招聘信息数量,因为每页显示15条,所以进一步计算即可得到总页数。1
2
3
4
5
6def totalPage(city,position):
json = get_json_data(city,position,'1')
total_info = json['content']['positionResult']['totalCount']
print('total job:{0}'.format(int(total_info)))
total_page = math.ceil(int(total_info)/15)
return total_page
写入csv文件
1 | def save_to_csv(position,city,job_list): |
以追加形式写入csv,并规定编码方式,否则会出现中文乱码的情况。
异常处理
由于网站的反爬虫机制,我们的爬虫在爬取数据的过程中很大可能会被识别,所以可以将写入csv文件的位置放在爬虫结束的地方,下次爬取从本次停止的页数开始,将结果继续追加写入文件。
结果说明
完整代码见lagou_job.py
运行本代码前,要先去获得自己的登录cookie,以及x-anti-forge-code和x-anti-forge-token的值,并填入代码中,1
2
3
4
5#获取x-anti-forge-code和x-anti-forge-token的值
r1 = requests.get('https://passport.lagou.com/login/login.html',headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',},)
X_Anti_Forge_Token = re.findall("X_Anti_Forge_Token = '(.*?)'", r1.text, re.S)[0]
X_Anti_Forge_Code = re.findall("X_Anti_Forge_Code = '(.*?)'", r1.text, re.S)[0]
print(X_Anti_Forge_Token,X_Anti_Forge_Code)
以杭州地区的python岗位为例,运行代码,得到的结果如下:
该搜索条件一共有137页结果,部分结果如下图所示:
如果想要获取其他城市其他职位的招聘信息,只需要修改city和position两个参数即可。
爬取到结果后,可以对数据进行进一步分析,得到更多信息。