实验目的
在之前的爬虫实战中,我们基于关键词搜索相关微信公众号文章,并得到了一系列相关的文章标题、链接等,找到自己需要的文章后,需要将其保存下来,本实验目的就是爬取微信公众号文章正文内容。
实验环境
python3
主要用到requests、pyquery库
步骤分析
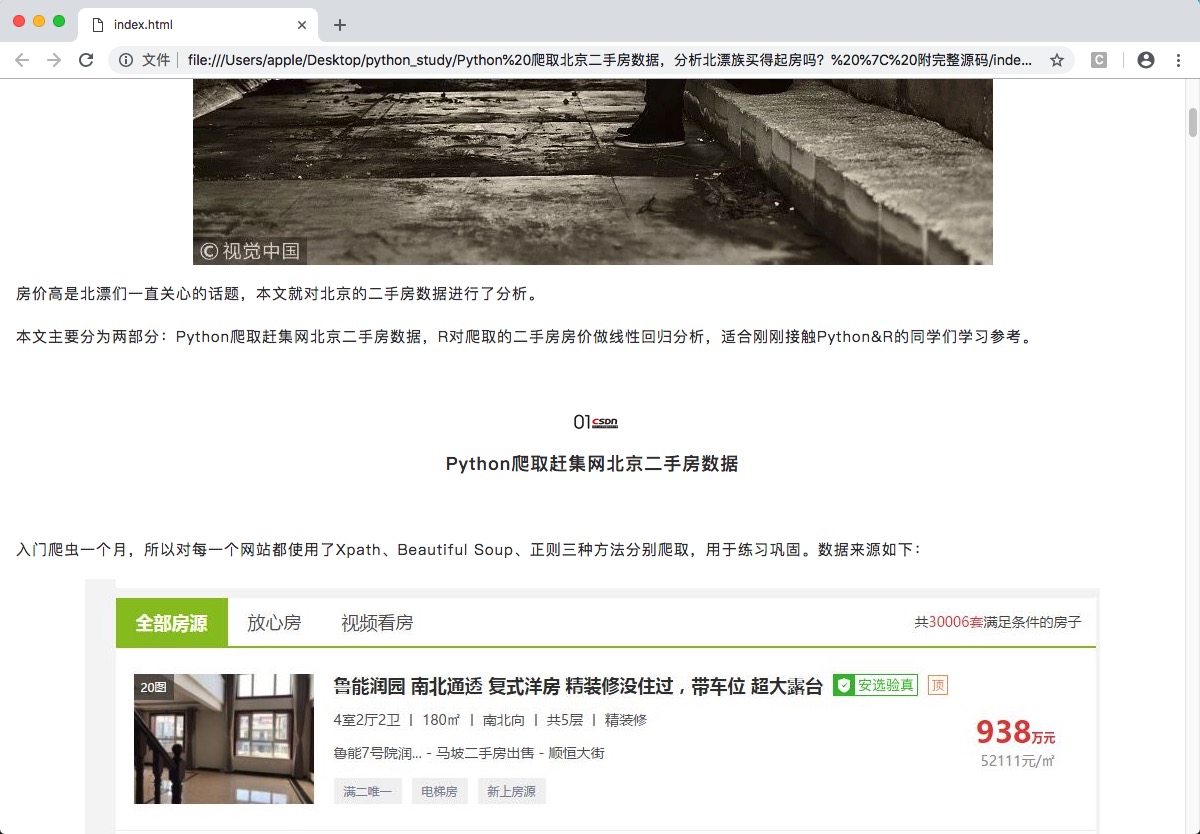
本文以CSDN公众号的一篇Python 爬取北京二手房数据,分析北漂族买得起房吗? | 附完整源码为例,
请求该网页后,获取到文章标题、作者、公众号信息、文章正文信息,由于我们要展示文章内容,所以为了确保文章正文的格式不被改变,我们提取其html格式,最后将所有提取到的内容组合成html格式,通过浏览器打开则能保持文章原来的格式。
要注意,文章中的所有图片都是来自网络上的,打开本地的html是无法解析出这些图片的,所以我们提取图片链接并下载保存到本地,并将html中的图片链接替换成本地位置。
实验过程
确定文章标题
文章标题位于如下位置:
1
2# 文章标题
title = doc.find('.rich_media_title').text()
确定公众号信息
作者信息、公众号来源、以及该公众号的微信号和简介,都可以通过pyquery进行提取: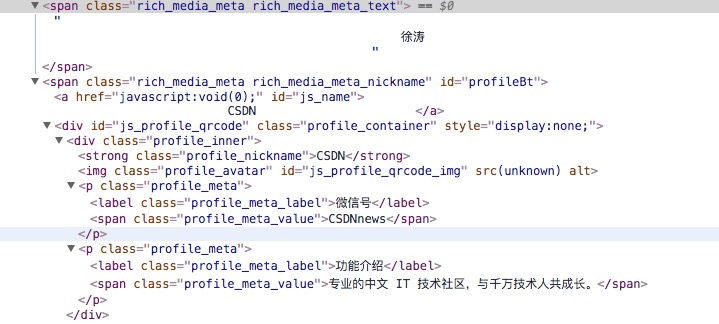
1
2
3
4# 微信公众号
author = doc.find('#meta_content .rich_media_meta_text').text()
source = doc.find('#js_name').text()
source_info = doc.find('.profile_meta_value').text()
确定文章内容
文章的正文内容不能通过text()进行提取,因为这样提取出的内容只有文字部分,而缺少格式,展示出来会非常难看,所以我们采用html()保留其正文部分的html元素:
1
2# 正文内容
content = doc.find('.rich_media_content')
提取所有图片链接
所有的图片链接都在img元素的data-src属性中:
1
2
3
4
5
6# 所有图片链接
pics_src = content.find('img').items()
for each in pics_src:
if '=' in each.attr('data-src'):
pic.append(each.attr('data-src'))
#print(pic)
下载图片
将文章中所有的图片下载并保存在本地文件中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def download_pic(title,url):
print(url)
pic_name = url.split('/')[4]
pic_type = url.split('=')[1]
response = requests.get(url,headers=random.choice(headers))
try:
if response.status_code == 200:
file_dir = "{0}/{1}".format(os.getcwd(), title)
if not os.path.isdir(file_dir):
os.mkdir(file_dir)
path = os.path.join(file_dir,pic_name+'.'+pic_type)
if not os.path.exists(path):
with open(path,'wb') as f:
f.write(response.content)
except:
pass
替换图片
将正文html中的图片链接替换成本地图片的链接,但是要注意,我们要在img元素中增加src属性,因为真正的图片链接是存放在这里的,然后把图片存放的位置作为src的属性值。1
2
3
4
5
6
7
8for item in content.find('img').items():
pic_url = item.attr('data-src')
if '=' in pic_url:
pic_name = pic_url.split('/')[4]
pic_type = pic_url.split('=')[1]
image = pic_name + '.' + pic_type
item.add_class('src')
item.attr('src',image)
生成index.html
将之前提取的文章标题、作者、公众号信息以html格式添入,生成index.html,打开即可查看微信正文内容。1
2
3
4
5
6
7
8
9file_dir = "{0}/{1}".format(os.getcwd(), title)
path = os.path.join(file_dir,'index.html')
index = '<h2>'+title+'</h2><br>'
index += '<span>'+author+''+source+'</span><br>'
index += '<span>'+source_info+'</span><br>'
index += content
with open(path, 'wb') as f:
f.write(index.encode('utf-8'))
结果分析与说明
完整代码见WeChat2.py
运行代码:1
python https://mp.weixin.qq.com/s/QAwrisNuu1dThFbs__wF_Q
爬取到的index.html如下: