实验目的
利用Selenium抓取淘宝商品并解析出商品的信息,包括图片、名称、价格、销量、店铺名称、店铺地址等信息,并将结果保存在数据库中。
实验环境
Chrome: -V 70
ChromeDriver: -V 2.43
确保已经安装python3的Selenium库、pyquery库
目标分析
总体思路
该爬虫的总体思路就是,给定要爬取的商品名称(keyword)、要爬取的起始页(start_page)和结束页(end_page),获取到该商品的搜索入口,并利用Selenium进行翻页动作,将各页的商品信息保存到文件或数据库中。
分步讲解
抓取的入口就是淘宝的搜索页面,例如搜索ipad,就可以直接访问https://s.taobao.com/search?q=iphone, 搜索结果如下图所示: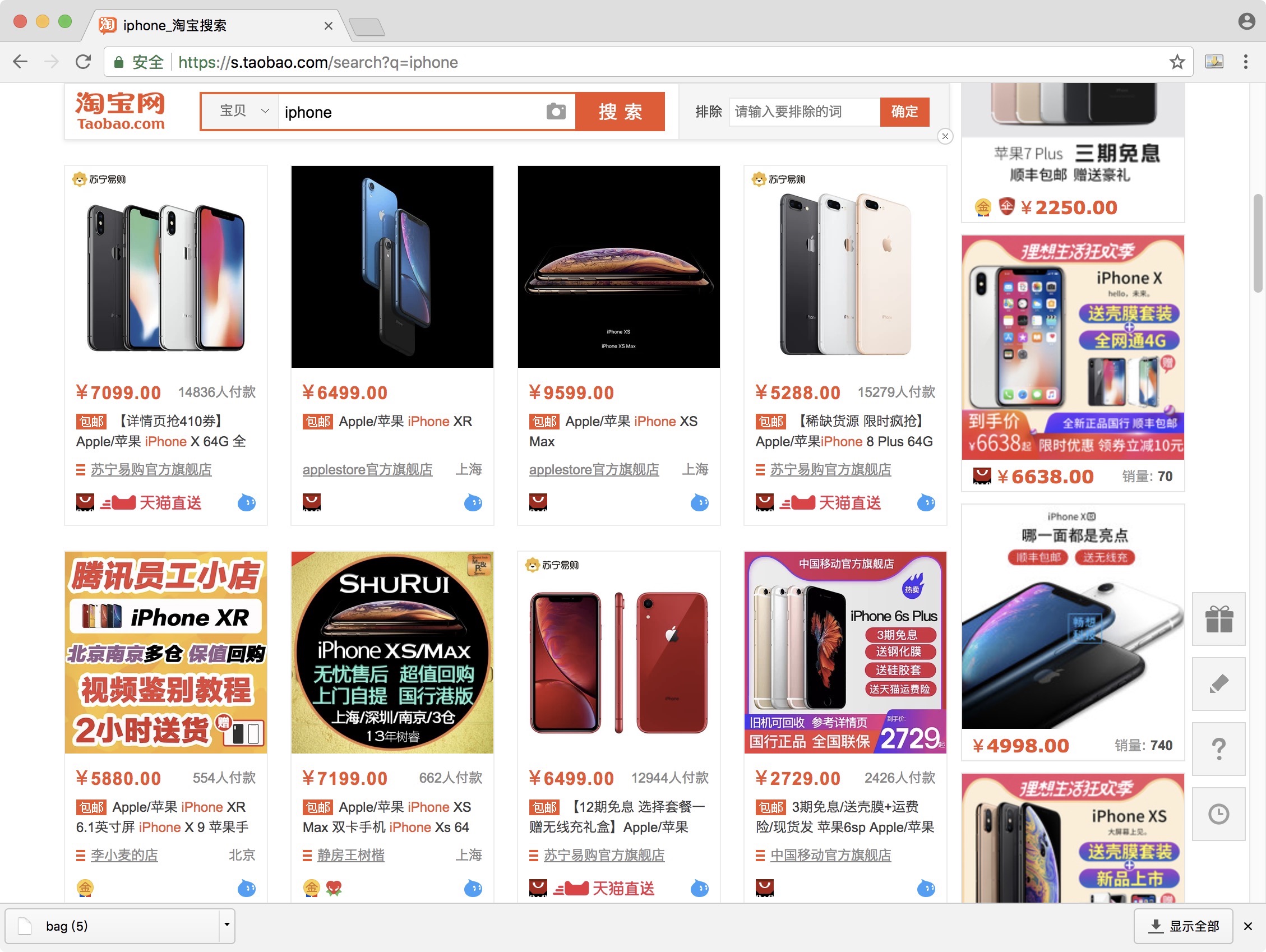
下图是一个商品条目,包含商品的价格、图片、名称、购买人数、店铺名称以及店铺所在地,我们要爬取的就是这些基本信息。
另外,在页面下方,可以看到分页导航:
该导航既可以直接点击下一页进行跳转,也可以输入页码进行跳转。但是并不是所有的商品都是100页的,所以还需要获取到要搜索商品的总页数,以便进行后续的页码遍历。
通过以上分析,本实验要做的就是通过Selenium获取页面源代码,用解析库pyquery解析出要爬取的基本信息。
实验步骤
获取总页数
因为每个商品的总页数不一样,所以我们还需要获得商品总页数。以iphone为例,查看页面源代码,可以看到在html中已经包含了总页数这一信息: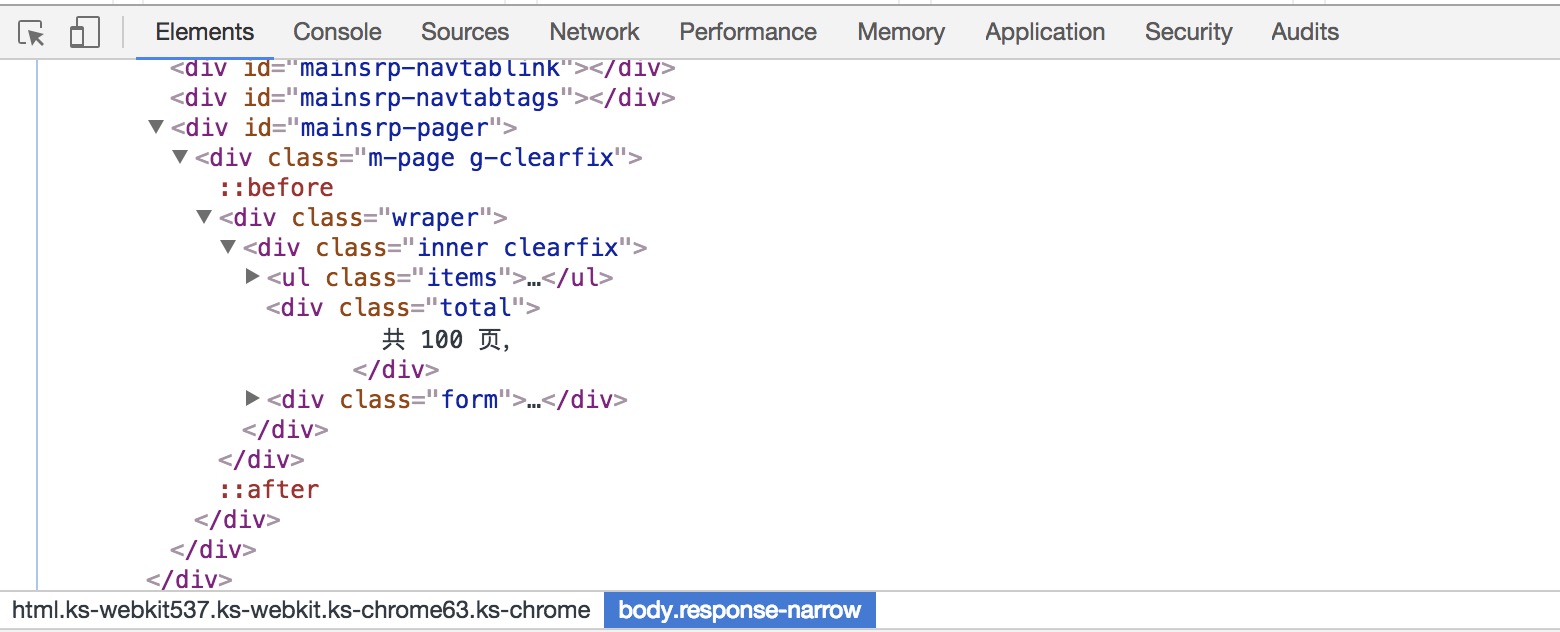
这里要做的就是提取出这一文本信息即可。1
2
3
4
5
6
7
8
9
10
11
12
13def total_page(keyword):
browser.get('https://www.taobao.com')
wait = WebDriverWait(browser,10)
inputbox = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm>div.search-button>button.btn-search.tb-bg')))
inputbox.clear()
inputbox.send_keys(keyword)
button.click()
totalPages = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager>div.m-page.g-clearfix>div.wraper>div.inner.clearfix>div.total'))).text
totalPages = re.search('(\d+)',totalPages).group(1)
return totalPages
例如,我想搜索“iphone”,得到的页数是:1
2
3page = total_page('iphone')
print(page)
# 100
实现翻页
因为搜索得到的结果很多,经过测试,一般最多为100页,如果我们要遍历每一页的内容,就要实现翻页功能。
我们可以使用Selenium来模拟翻页动作。这里有两种选择,一种是直接点击下一页来获取下一页的内容,另一种是在页码输入框中输入要跳转的页码,然后点击确定键进行跳转。我们选择后者,原因是如果爬取过程中出现异常退出,例如在第50页的时候退出了,点击“下一页”时,就无法快速切换到刚才中止的位置,需要记录当前的页码数,并做异常检测,整个过程比较复杂,所以我们直接用跳转的方式来爬取页面。1
2
3
4
5
6
7def next_page(currentPage):
wait = WebDriverWait(browser, 10)
inputbox = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div> input.input.J_Input')))
button = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div>span.btn.J_Submit')))
inputbox.clear()
inputbox.send_keys(int(currentPage))
button.click()
例如,搜索iphone商品,并想跳转到40页,跳转结果如下:
获取商品信息
得到页面源代码后,我们要解析页面,得到商品列表,获取商品的基本信息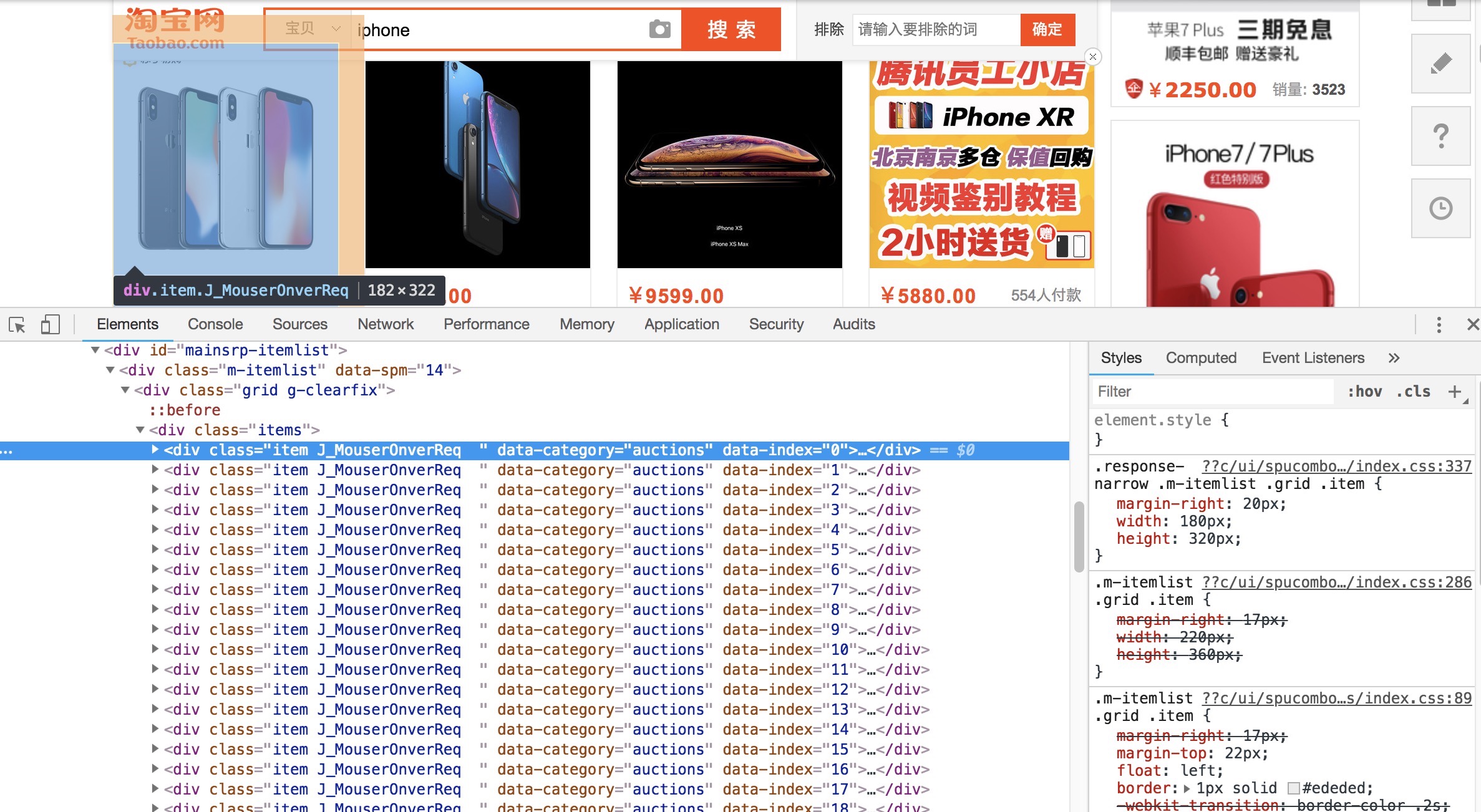
可以发现,所有的商品都包含在id=“mainsrp-itemlist”下的items.item条目中,点开每一个item,都是一个商品的基本信息。所以我们只需要从页源代码中提取出这些基本信息即可。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20def product_info():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-itemlist .items .item')))
#获取页面源代码
html = browser.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
product_list = []
for item in items:
product = {
'image':item.find('.pic .img').attr('data-src'),
'price':item.find('.price').text().replace('\n',''),
'deal':item.find('.deal-cnt').text(),
'title':item.find('.title').text().replace('\n',' '),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
product_list.append(product)
#save_to_csv(keyword,product_list)
#save_to_mongo(product)
例如爬取iphone商品列表的第二页,得到的结果如下所示:
保存爬取结果
为了美观与方便起见,我们可以把爬取到的内容保存起来,常见的有保存到数据库中,也可以直接保存成csv表。1
2
3
4
5
6
7
8def save_to_csv(keyword,product_list):
file_dir = "{0}/{1}".format(os.getcwd(), "product")
if not os.path.isdir(file_dir):
os.makedirs(file_dir)
path = os.path.join(file_dir,keyword+".csv")
dataframe = pd.DataFrame(product_list)
columns = ['image','price','deal','title','shop','location']
dataframe.to_csv(path,mode='a',encoding="utf_8_sig",columns=columns)
当前py文件的路径下创建一个product文件夹,将所有的商品信息保存在keyword.csv中。注意这里对列名进行了设置,设置保存的列顺序,否则pandas会重新排序。
以iphone的第二页商品列表为例,结果如下:
代码整合
以上代码分别实现了商品的搜索、翻页以及提取每页信息的功能。剩下要做的就是整合这些代码,设定搜索商品的名称以及要提取的页数这些参数信息,得到最终的商品信息文件。
下面是一个示例,爬取ipad的第三页到第五页的内容1
2
3
4# keyword = 'ipad'
# start_page = '3'
# end_page = '5'
python Selenium.py ipad 3 5

淘宝搜索ipad,3-5页的内容已经保存到ipad.csv中,路径在结果中给出。
总结说明
完整的代码保存在Selenium_TB.py
最后一点说明:在淘宝进行搜索时,有时可能出现用户登录的跳转,可以使用手机扫码登录,不要使用用户名密码登录的方法,因为由于使用Selenium,在滑块验证的时候,淘宝UA在CAPTCHA人机识别上无法蒙混过去。另外,有时候运行错误可能是因为网速或者登录的时间超过了我们设定的时间,可以自行去代码里更改参数。