实验目的
通过在头条的搜索栏搜索关键词,分析Ajax请求,将搜索结果的图集以文件夹形式下载并保存到本地
抓取分析
打开搜索栏,比如我们搜索的keyword是“国庆”,查看图集栏目,结果如图所示: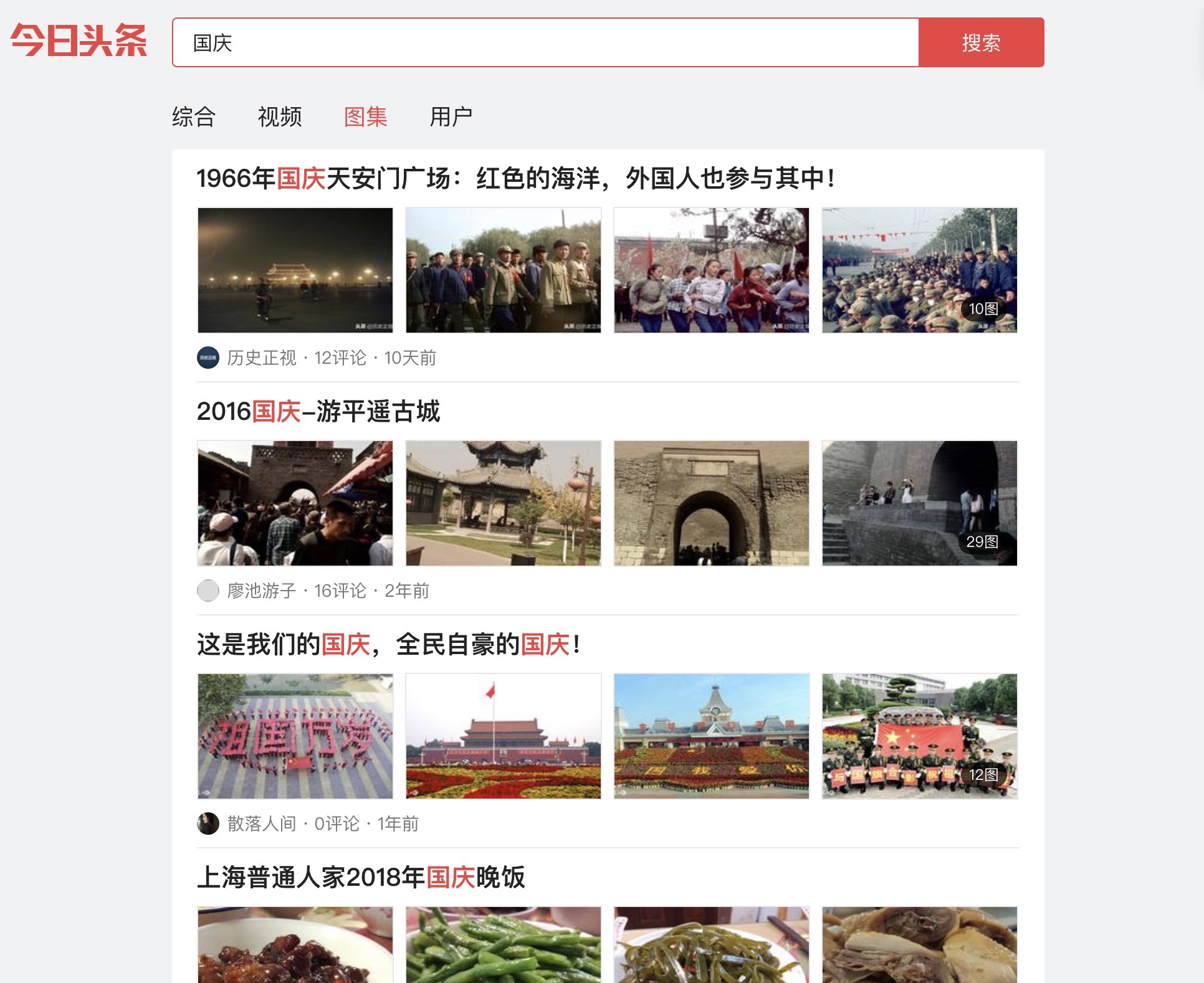
打开开发者工具,刷新要爬取的页面,打开第一个请求,该请求的URL就是当前网页的链接:https://www.toutiao.com/search/?keyword=%E5%9B%BD%E5%BA%86,打开Preview选项卡,如果该页面的内容是根据第一个请求得到的结果渲染出来的,那么第一个请求的源代码中一定会包含页面结果中的文字。于是我们搜索了结果的标题“平遥古城”,如下图所示: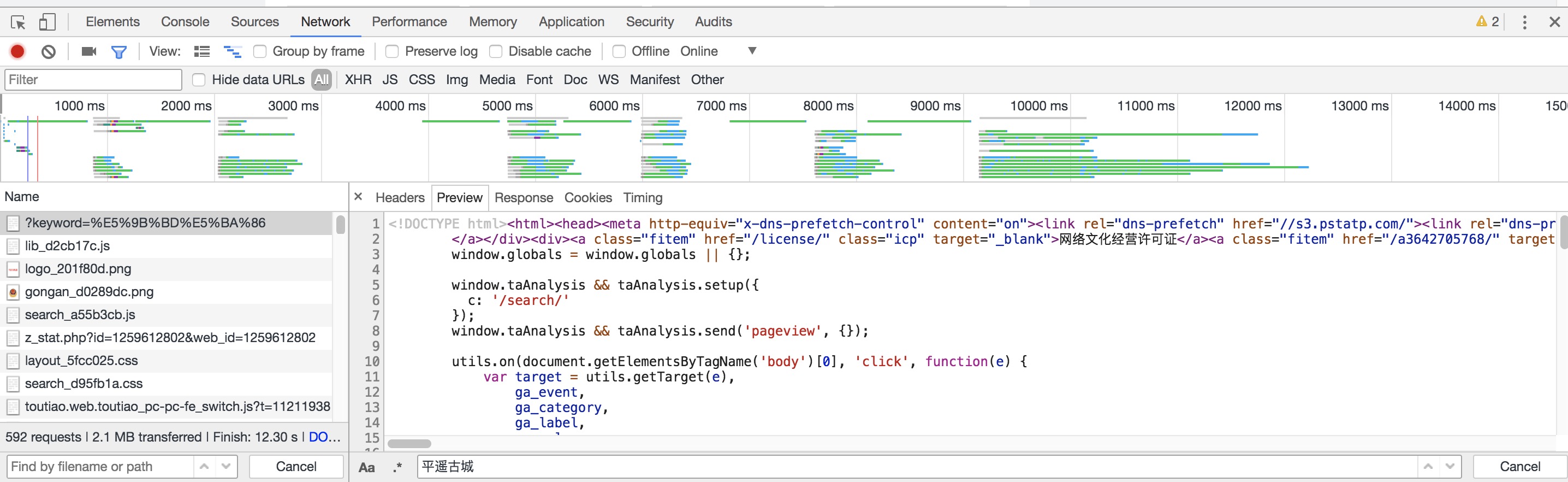
我们发现网页源代码中并没有包含该结果,搜索匹配结果数目为0。因此,我们可以初步判断,这些内容可能是由Ajax加载的,然后由JS渲染出来。
下一步,我们切换到XHR过滤选项卡,查看一下有没有Ajax请求。
查看请求,发现是比较常规的Ajax请求格式,滚动页面,Ajax请求不断增加。点开一个Ajax请求,查看结果是否包含页面中的相关数据: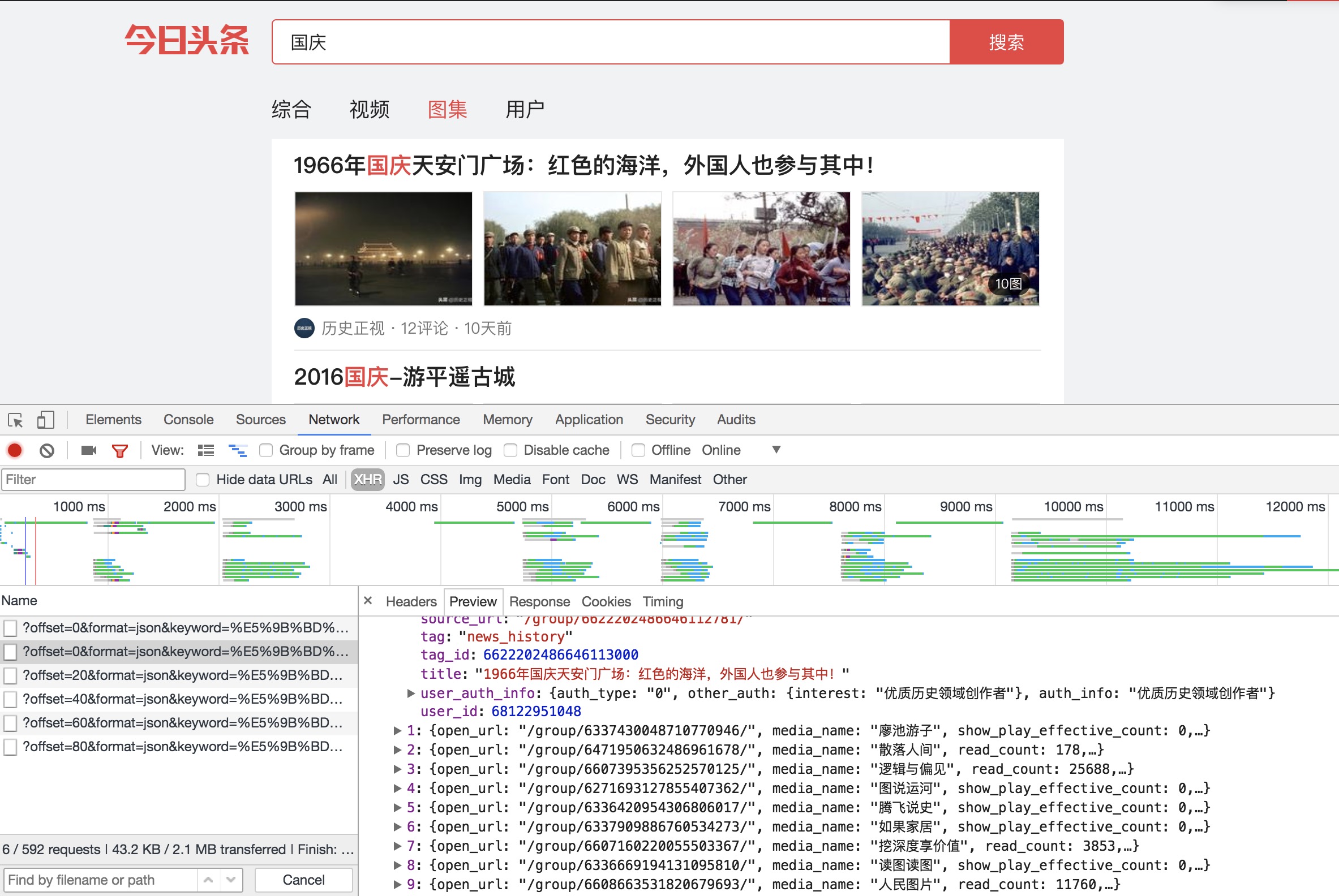
点开data字段,出现许多条数据,在第一条数据下,查看title字段,与页面的第一条数据的标题一致,同时检查了其他数据,也正好是对应的。所以,我们可以判断这些数据的确是由Ajax加载的。
我们的目的是抓取这些图片并将每一组图片分别以文件夹的形式下载并保存在本地,查看data字段,可以发现一个叫做group_id的字段,与该组图片的源页面url相关,所以我们可以根据该字段构造url,分别去每一组图片的源页面下载并保存图片。
打开任意一组图片的源页面,可以发现,当前图集所有图片的url均写作正则的形式: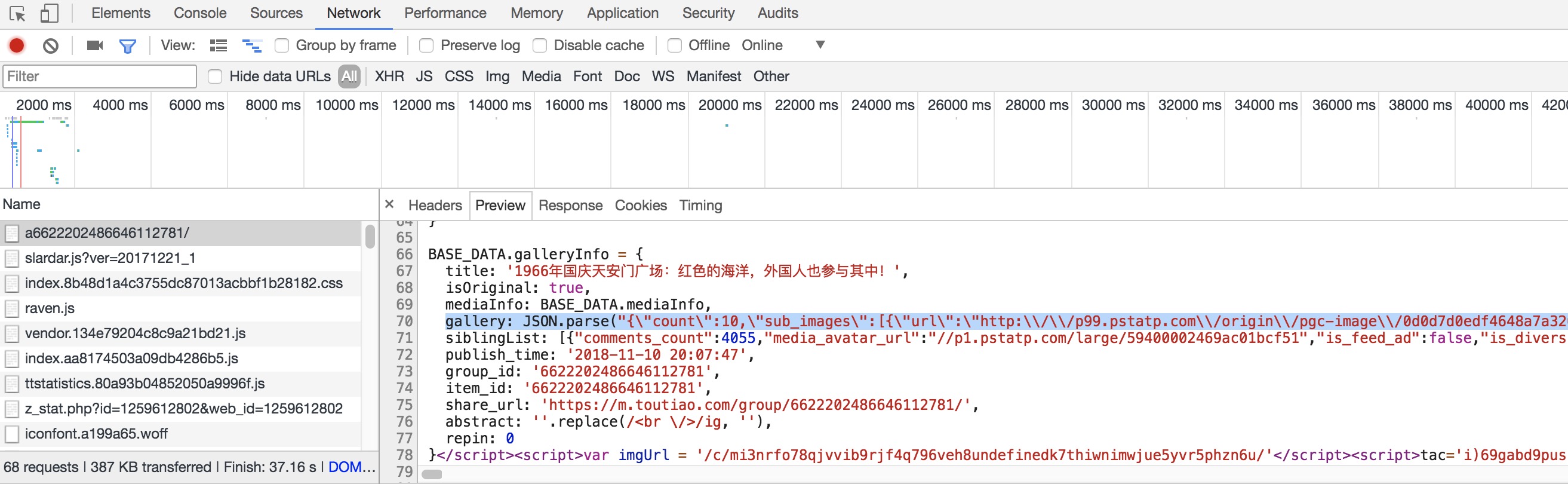
可以看到,正则中的count值刚好与之前的gallary_image_count吻合。
综上分析,我们要做的就是提取图片栏目的group_id,分别到各条数据的页面下,解析出图片链接的正则表达式,提取链接并下载保存到本地。
功能实现
首先是要实现get_page()方法,来加载单个Ajax请求的结果。
通过开发者工具,可以发现每个Ajax请求的URL格式如下:1
2
3https://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E5%9B%BD%E5%BA%86&autoload=true&count=20&cur_tab=3&from=gallery
https://www.toutiao.com/search_content/?offset=20&format=json&keyword=%E5%9B%BD%E5%BA%86&autoload=true&count=20&cur_tab=3&from=gallery
https://www.toutiao.com/search_content/?offset=40&format=json&keyword=%E5%9B%BD%E5%BA%86&autoload=true&count=20&cur_tab=3&from=gallery
观察发现只有offset不一样,所以可以通过传入不同的offset,获得不同的Ajax请求。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import requests
import random
headers = [
{'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0'},
{'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'},
{'User-Agent': 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11'},
{'User-Agent': 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)'},
{'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:40.0) Gecko/20100101 Firefox/40.0'},
{'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36'}
]
def get_page(url):
params = {
'offset':offset,
'format':'json',
'keyword':'国庆',
'aotoload':'true',
'count':'20',
'cur_tab':'1',
'from':'gallery',
}
url = 'https://www.toutiao.com/search_content/?'+urlencode(params)
try:
response = requests.get(url,headers=random.choice(headers))
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error',e.args)
我们用urlencode()构造请求的GET参数,然后用requests请求该链接,如果返回的状态码是200,则返回JSON的结果。
接下来,要实现解析方法,从每个Ajax请求中,提取每条数据的group_id字段的值,来构造新的url,供后面提取图片使用。1
2
3
4
5
6
7def get_url(Ajax_json):
if Ajax_json.get('data'):
items = Ajax_json.get('data')
for item in items:
group_id = item.get('group_id')
page_url = 'https://www.toutiao.com/a'+str(group_id)
yield page_url
构造出每个Ajax请求中的图片来源页面url后,我们要做的就是解析各个链接,根据图片的正则表达式,提取出图片链接。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def parse_page(page_url):
page_dict = {} #存放标题和图片链接
response = requests.get(page_url,headers = random.choice(headers))
doc = pq(response.text)
#获取文章标题
title = doc('title').text()
pattern = re.compile('gallery: JSON.parse\("(.*?)"\)',re.S)
results = re.findall(pattern,response.text)
if results:
results = results[0].replace('\\','')
data = json.loads(results)
url_list = data.get('sub_images')
page_dict['title'] = title
page_dict['images'] = [each.get('url')for each in url_list]
return page_dict
得到每组图片的标题和链接后,我们就可以开始下载并保存图片了1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def download_images(keyword,title,image_url):
response = requests.get(image_url,headers=random.choice(headers))
if response.status_code == 200:
file_dir = "{0}/{1}/{2}/{3}".format(os.getcwd(), "images",keyword,title)
if not os.path.isdir(file_dir):
os.makedirs(file_dir)
path = os.path.join(file_dir,hashlib.md5(response.content).hexdigest()+".jpg")
if not os.path.exists(path):
with open(path,'wb') as f:
f.write(response.content)
#print('Download image:', image_url)
#else:
#print('Already existed')
在该方法中,我们根据搜索的关键词建立文件夹,然后根据title建立每组图片的文件夹,请求每组图片的链接,获取图片的二进制数据,以二进制形式形如文件。图片的名称使用其内容的MD5值,这样可以去除重复。
通过页面分析,我们知道每个Ajax请求的URL链接只有offset不同,那么只要构造一个offset数组,并遍历,就可以对每个请求进行图片的链接提取以及下载行为了。
另外,我们还可以开启多进程下载图片,提高速度。
最后,为了让该爬虫爬取我们想要的图集和页数,只需要引入sys,给爬虫传入参数即可。
完整代码可以看Ajax_test.py
结果测试
运行爬虫,爬取头条上与“开学”有关的图集,这里只爬取前两页的内容。1
python Ajax_test.py 开学 1 2
可以看到,以每组图集所在的文章标题为文件夹标题,在“开学”文件夹下生成了相应的文件夹,其中保存了相关图片: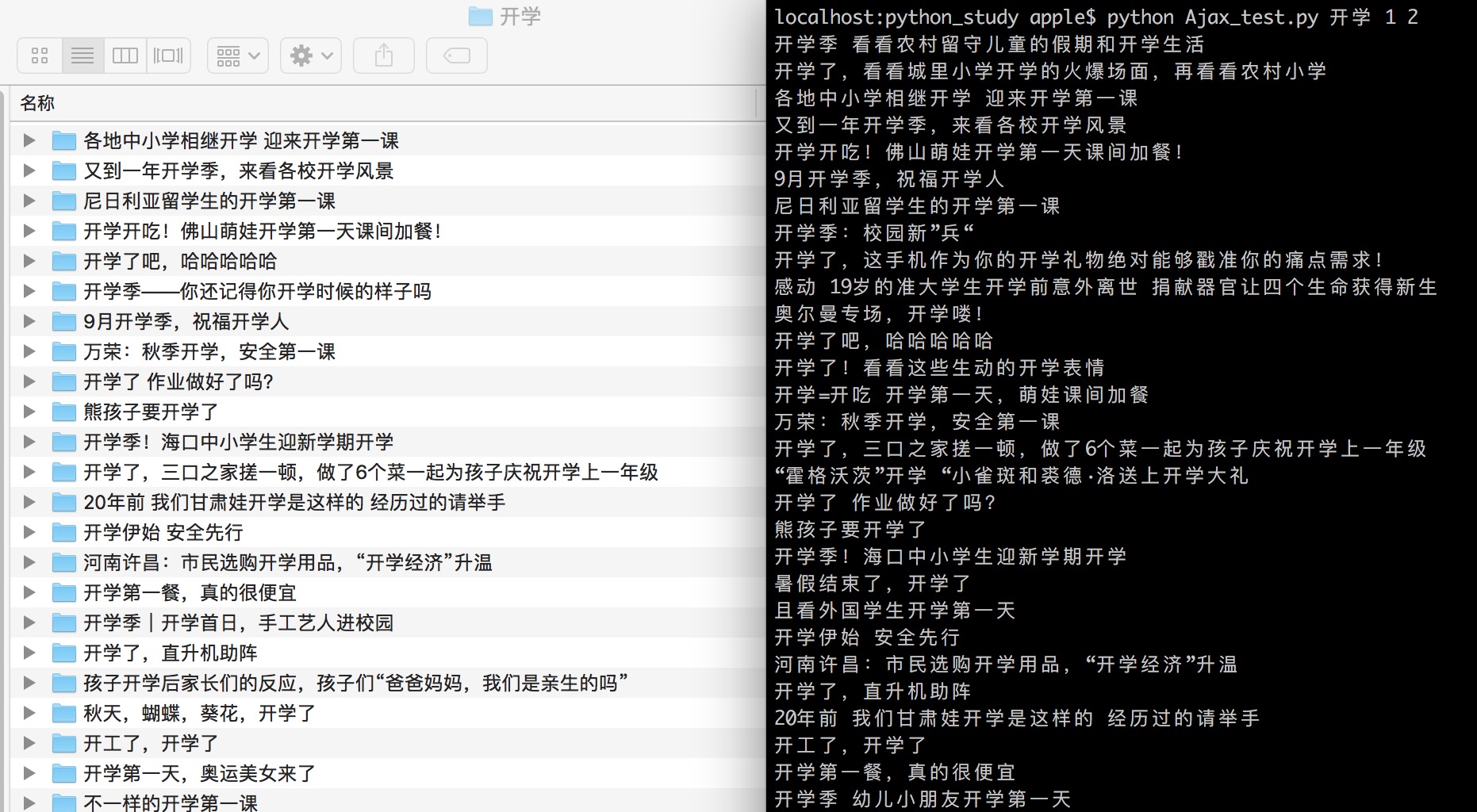
打开任意文件夹,可以看到已经下载并保存了相关图片: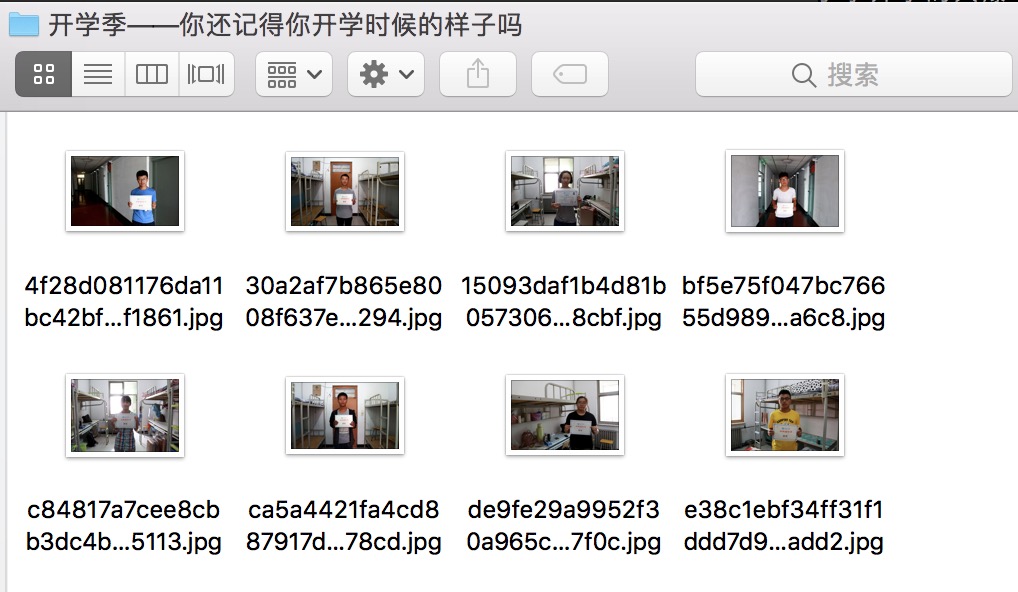
以上就是分析Ajax请求并爬取相关内容的一个小实验,开启下一章的学习吧~~~~