这一章主要就是学习数据存储的相关内容。
解析器解析出数据后,可以保存为txt、json、csv等文本文件,还可以保存到数据库中,比如关系型数据库MySQL、非关系型数据库MongoDB、Redis等。
文件存储
文本文件存储
存储为文本文件十分简单,缺点就是不便于检索。
下面以一个实例来看看过程:保存知乎上“发现”页面的“热门话题”部分,将问题与答案统一保存为文本形式1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import requests
import random
from pyquery import PyQuery
url = "https://www.zhihu.com/explore"
headers = [
{'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0'},
{'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'},
{'User-Agent': 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11'},
{'User-Agent': 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)'},
{'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:40.0) Gecko/20100101 Firefox/40.0'},
{'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36'}
]
html = requests.get(url,headers=random.choice(headers))
doc = PyQuery(html.text)
items = doc('.explore-feed').items()
for each in items:
question = each('.question_link').text()
author = each('.author-link').text()
answer = PyQuery(each('.content').html()).text()
with open('zhihu.txt','a+',encoding='utf-8') as f:
f.write('\n'.join([question,author,answer]))
f.write('\n'+'='*50+'\n')
我们会得到一个叫做zhihu.txt的文本,里面保存了热门话题的问题以及回答者还有回答内容
JSON文件存储
JavaScript Object Notation,即JavaScript对象标记,通过对象和数组的组合来表示数据,是一种轻量级的数据交换格式。
对象:{key1:value1,key2:value2,…},可以嵌套
数组:用[]包裹
一个JSON对象举例如下:1
2
3
4
5
6
7
8
9[{
"name":"Alice",
"gender":"female",
"age":3
},{
"name":"Bob",
"gender":"male",
"age":4
}]
- 读取JSON:
python提供了JSON库来实现读写操作
loads():将JSON文本字符串转化为JSON对象
dumps():将JSON对象转化为文本字符串1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import json
#JSON的数据必须要双引号包围
str = '''
[{
"name":"Alice",
"gender":"female",
"age":3
},{
"name":"Bob",
"gender":"male",
"age":4
}]
'''
print(type(str))
#<class 'str'>
data = json.loads(str)
print(data)
print(type(data))
# [{'name': 'Alice', 'gender': 'female', 'age': 3}, {'name': 'Bob', 'gender': 'male', 'age': 4}]
# <class 'list'>
注意:JSON的数据需要用双引号来包围,不能用单引号,否则loads()方法无法解析
- 输出JSON:
用dumps()方法将JSON对象转化为字符串1
2
3
4
5
6
7import json
data = [{'name': 'Alice', 'gender': 'female', 'age': 3}, {'name': 'Bob', 'gender': 'male', 'age': 4}]
data_str = json.dumps(data)
print(data_str)
print(type(data_str))
# [{"name": "Alice", "gender": "female", "age": 3}, {"name": "Bob", "gender": "male", "age": 4}]
# <class 'str'>
如果要把JSON数据保存到文本中,可以在dumps中加入一个参数:indent=2,这样得到的内容会自带缩进。
如果JSON中包含中文,直接转换会变成unicode字符,可以在dumps中指定ensure_ascii=False,规定文件输出的编码1
2with open('data.json','w',encoding='utf-8') as file:
file.write(json.dumps(data,indent=2,ensure_ascii=False))
CSV文件存储
Comma-Separated Values,逗号/字符分隔符,以纯文本形式存储表格数据
该文件由任意数目的记录组成,记录间以某种换行符分割。
- 写入
1 | import csv |
可以看到得到的文件如下图: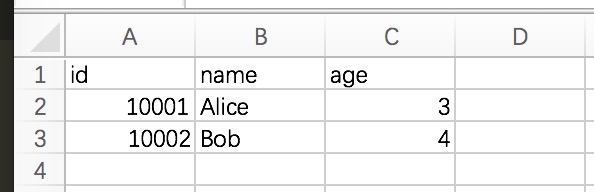
写入的文本默认以逗号分隔,如果要修改列之间的分隔符,传入delimiter参数:1
2
3
4writer = csv.writer(csvfile,delimiter=' ')#以空格分隔
#id name age
#10001 Alice 3
#10002 Bob 4
writerow()只能一行一行写入,可以直接用writerows()同时写入多行,参数为二维列表:1
2writer.writerow(['id','name','age'])
writer.writerows([['10001','Alice',3],['10002','Bob',4]])
不过爬虫爬取的一般都是结构化数据,一般用字典来表示,所以将数据以字典形式写进CSV:1
2
3
4
5
6
7import csv
with open('data.csv','w') as csvfile:
fieldnames = ['id','name','age']
writer = csv.DictWriter(csvfile,fieldnames=fieldnames) #初始化字典写入对象
writer.writeheader() #可以先写入头信息
writer.writerow({'id':'10001','name':'Alice','age':3})
writer.writerow({'id':'10002','name':'Bob','age':4})
写入中文的话,给open()传入encoding=‘utf-8’参数即可。
- 读取
1 | import csv |
或者用pandas:1
2
3
4
5
6import pandas as pd
df = pd.read_csv('data.csv')
print(df)
# id name age
# 0 10001 Alice 3
# 1 10002 Bob 4
关系型数据库存储
基于关系模型的数据库,关系模型通过二维表来保存
关系型数据库有很多,比如SQLite、MySQL、Oracle、SQL Serve、DB2等
这章主要介绍的就是py3下MySQL的存储,使用PyMySQL库
连接数据库
1 | import pymysql |
首先用connect方法声明一个mysql链接对象,这里由于在本地运行,所以传入localhost
连接成功后,用cursor()方法获得mysql的操作游标,利用游标来执行sql语句,随后用execute()方法执行,然后用fetchone()方法获得第一条数据,即版本号。
创建表
1 | import pymysql |
在spiders数据库上创建一个名为students的表
插入数据
1 | import pymysql |
用commit()方法实现数据插入,对数据的插入、删除、更新都需要该方法
但上面这种写法,如果突然增加一个字段,就得改SQL语句,所以最好是有一个通用的插入方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17data = {
'id':'20120001',
'name':'Alice',
'age':3
}
table = 'students'
keys = ','.join(data.keys())
values = ','.join(['%s']*len(data))
sql = 'INSERT INTO {table}({keys}) VALUES ({values})'.format(table=table,keys=keys,values=values)
try:
if cursor.execute(sql,tuple(data.values())):
print('Successful')
db.commit()
except:
print('Failed')
db.rollback()
db.close()
更新数据
如果数据存在,则更新数据,如果不存在,则插入数据1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import pymysql
db = pymysql.connect(host='localhost',user='root',password='root',port=3306,db='spiders')
cursor = db.cursor()
data = {
'id':'20120001',
'name':'Alice',
'age':4
}
table = 'students'
keys = ','.join(data.keys())
values = ','.join(['%s']*len(data))
sql = 'INSERT INTO {table}({keys}) VALUES ({values}) ON DUPLICATE KEY UPDATE '.format(table=table,keys=keys,values=values)
update = ','.join(["{key}=%s".format(key=key) for key in data])
sql += update
if cursor.execute(sql,tuple(data.values())*2):
print('Successful')
db.commit()
db.close()
ON DUPLICATE KEY UPDATE意思就是如果如果主键已经存在,则更新数据记录,不存在则插入数据
删除数据
指定删除的目标表名和删除条件,并且要使用commit()1
2
3
4
5
6
7
8
9
10
11
12
13import pymysql
db = pymysql.connect(host='localhost',user='root',password='root',port=3306,db='spiders')
cursor = db.cursor()
table = 'students'
condition = 'age > 4'
sql = 'DELETE FROM {table} WHERE {condition}'.format(table=table,condition=condition)
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()
db.close()
查询数据
1 | import pymysql |
rowcount可以获取查询结果的条数
fetchone()是用哦你过来获取结果的第一条数据,结果是元组形式
fetchall()是获取所有结果的数据,但是它的内部实现是有一个指针来指向查询结果,前面已经查询了第一条数据,所以这里是从第二条数据开始查询的
如果想要获取所有的结果数据,可以用while+fetchone()的方法,减小开销:1
2
3
4
5
6
7
8
9
10sql = 'SELECT * FROM students WHERE age >=5'
try:
cursor.execute(sql)
print('Count:',cursor.rowcount)
row = cursor.fetchone()
while row:
print('Row:',row)
row = cursor.fetchone()
except:
print('Error')
非关系型数据库存储
NoSQL,Not Only SQL,泛指关系型数据库。NoSQL是基于键值对的,不需要SQL层的解析,数据之间没有耦合性,性能非常高。
非关系型数据库可以分类如下:
1.键值存储数据库:Redis/Voldemort/Oracle BDB等
2.列存储数据库:Cassandra/HBase/Riak等
3.文档型数据库:CouchDB/MongoDB等
4.图形数据库:Neo4J/InfoGrid/Infinite Graph等
对于爬虫的数据存储而言,有时候某条数据的某个字段可能因为提取失败而缺失,或是要随时调整,或者数据存在嵌套关系,这种情况对于关系型数据库来说,操作很繁琐,而对于NoSQL来说就比较高效。
这里主要介绍了Redis和MongdoDB的数据存储操作。
MongoDB存储
1.连接Mongo、指定数据库、指定集合
mongo中可以建立多个数据库,所以要指定操作哪个数据库
每个数据库包含多个集合,类似于关系数据库中的表1
2
3
4
5
6
7
8
9
10
11
12
13
14import pymongo
#连接Mongo
client = pymongo.MongoClient(host='localhost',port=27017)
#client = pymongo.MongoClient('mongodb://localhost:27017')
#指定数据库test
db = client.test
#db = client['test']
#这里要进行一个用户认证,因为在配置的时候设置了认证选项
db.authenticate('admin','password')
#指定集合students
collection = db.students
#collection = db['students']
2.插入数据
在students集合中插入一条学生数据,该数据以字典形式表示1
2
3
4
5
6
7
8
9student = {
'ID':'201810001',
'name':'Alice',
'age':3,
'gender':'female'
}
result = collection.insert(student)
print(result)
#5bebc4875f627da9cf8e27df
每条数据都有一个_id属性来唯一标识,insert方法执行后返回_id值
可以同时插入多条数据,以列表形式传递即可:collection.insert([stu1,stu2]),返回的也是_id的集合
不过在Mongo3.x中,更推荐使用insert_one()和insert_many():1
2
3
4
5
6
7result = collection.insert_one(stu1)
print(result) #返回InsertOneResult对象
print(result.inserted_id) #获得_id
result = collection.insert_many([stu1,stu2])
print(result)
print(result.inserted_ids)
3.查询
find_one()查询单个结果,find()返回一个生成器对象1
2
3
4
5result = collection.find_one({'name':'Alice'})
print(type(result))
print(result)
#{'_id': ObjectId('5bebc3fd5f627da98d993639')
#'ID': '201810001', 'name': 'Alice', 'age': 3, 'gender': 'female'}
也可以根据ObjectId看来查询,使用bson库中的objectid:1
2
3
4
5from bson.objectid import ObjectId
result = collection.find_one({'_id':ObjectId('5bebc3fd5f627da98d993639')})
print(result)
#查询结果是字典类型,如果查询结果不存在,返回None
#{'_id': ObjectId('5bebc4875f627da9cf8e27df'), 'ID': '201810001', 'name': 'Alice', 'age': 3, '
查询年龄大于3的数据:1
2
3result = collection.find({'age':{'$gt':3}})
print(result)
#<pymongo.cursor.Cursor object at 0x7fa90e599940>
| 符号 | 含义 | 实例 |
|---|---|---|
| $lt | 小于 | {‘age’:{‘$lt’:20}} |
| $gt | 大于 | {‘age’:{‘$gt’:20}} |
| $lte | 小于等于 | {‘age’:{‘$lte’:20}} |
| $gte | 大于等于 | {‘age’:{‘$gte’:20}} |
| $ne | 不等于 | {‘age’:{‘$ne’:20}} |
| $in | 在范围内 | {‘age’:{‘$in’:[20,23]}} |
| $nin | 不在范围内 | {‘age’:{‘$nin’:[20,23]}} |
也可以用正则匹配查询:1
2result = collection.find({'name':{'$regex':'^M*'}})
#查询以M开头的名字
除了$regex,还有$exists、$type、$mod等操作,具体的可以自行查阅
4.计数
查询结果有多少条数据,可以用count()1
result = collection.find().count()
5.排序
用sort(),并传入排序的字段及升降标志1
2
3results = collection.find().sort('ID',pymongo.DESCENDING)
print([result['ID'] for result in results])
#pymongo.ASCENDING or DESCENDING
6.偏移
有时候想跳过几个元素,可以用skip()方法,偏移n个位置,就skip(n)1
2results = collection.find().sort('name',pymongo.ASCENDING).skip(30)
print([result['name'] for result in results])
也可以用limit()方法指定要取得结果个数1
2results = collection.find().sort('name',pymongo.ASCENDING).skip(30).limit(1)#只取一个
print([result['name'] for result in results])
7.更新
update_one()或update_many(),指定更新的条件和更新后的数据1
2
3
4
5
6
7
8condition = {'name':'Alice'}
student = collection.find_one(condition)
student['age'] = 25
result = collection.update_one(condition,{'$set':student})
print(result.matched_count,result.modified_count)
condition = {'age':{'$gt':3}}
result = collection.update_many(conditon,{'$inc':{'age':1}}) #年龄+1
8.删除
remove()1
results = collection.remove({'name':'Bob'})
不过更推荐下面的两种方法:1
2
3
4
5result = collection.delete_one({'name':'Bob'})#删除第一条符合条件的数据
print(result)
print(result.delete_count)
result = collection.delete_many({'age':{'$gt':3}})#删除所有符合条件的数据
9.其他
pymongo还提供了一些组合方法,比如find_one_and_delete()、find_one_and_replace()等
Redis存储
首先连接redis1
2
3
4
5
6from redis import StrictRedis
#host='localhost',port=6379,db=0,默认不传的情况下的值,password我们之前自己设置了
redis = StrictRedis(host='localhost',port=6379,db=0,password='password')
redis.set('name','Bob')
print(redis.get('name'))
#b'Bob'
还可以这样连接:1
2
3from redis import StrictRedis,ConnectionPool
pool = ConnectionPool(host='localhost',port=6379,db=0,password='password')
redis = StrictRedis(connection_pool=pool)
也可以通过构造url传给ConnectionPort:1
2
3
4
5
6
7
8
9'''
redis://[:password]@host:post/db #创建Redis TCP连接
rediss://[:password]@host:post/db #创建Redis TCP+SSL
unix://[:password]@/path/to/socket.sock?db=db #创建Redis UNIX socket连接
'''
from redis import StrictRedis,ConnectionPool
url = 'redis://:password@localhost:6379/db'
pool = ConnectionPool.from_url(url)
redis = StrictRedis(connection_pool=pool)
键操作:
| 方法 | 作用 | 示例 | 示例结果 |
|---|---|---|---|
| exists(name) | 判断一个键是否存在 | redis.exists(‘name’) | true |
| delete(name) | 删除一个键 | redis.exists(‘name’) | 1 |
| type(name) | 判断键类型 | redis.type(name) | b’string’ |
| keys(pattern) | 获取所有符合re规则的键 | redis.keys(‘n*’) | [b’name’] |
| randomkey() | 获取随机的一个键 | randomkey() | b’name’ |
| rename(src,dst) | 重命名键 src:原,dst:新 | redis.rename(‘name’,’nickname’) | True |
| dbsize() | 获取当前数据库中键的数目 | dbsize() | 100 |
| expire(name,time) | 设定键的过期时间,单位秒 | redis.expire(‘name’,2) | True |
| ttl(name) | 获取键的过期时间,单位秒,-1表示永不过期 | redis.ttl(‘name’) | -1 |
| move(name,db) | 将键移动到其他数据库 | move(‘name’,2) | True |
| flushdb() | 删除当前选择数据库中的所有键 | flushdb() | True |
| flushall() | 删除所有数据库中的所有键 | flushall() | True |
这些操作太多了,需要的时候再去查就行了。
- 字符串操作:
getset(name,value):给name赋值value,并返回上次的value
mget(keys,*args):返回多个键对应的value组成的列表,如mget([‘name’,’nickname’]) [b’mike’,b’miker’] - 列表操作
- 集合操作
- 有序集合操作
- 散列操作
RedisDump提供了强大的Redis数据导入和导出功能:
redis-dump用于导出数据
redis-load用于导入数据