目标分析
目标站点:https://movie.douban.com/top250
目标信息:豆瓣电影Top250中每部影片的片名、评分、图片、排名等信息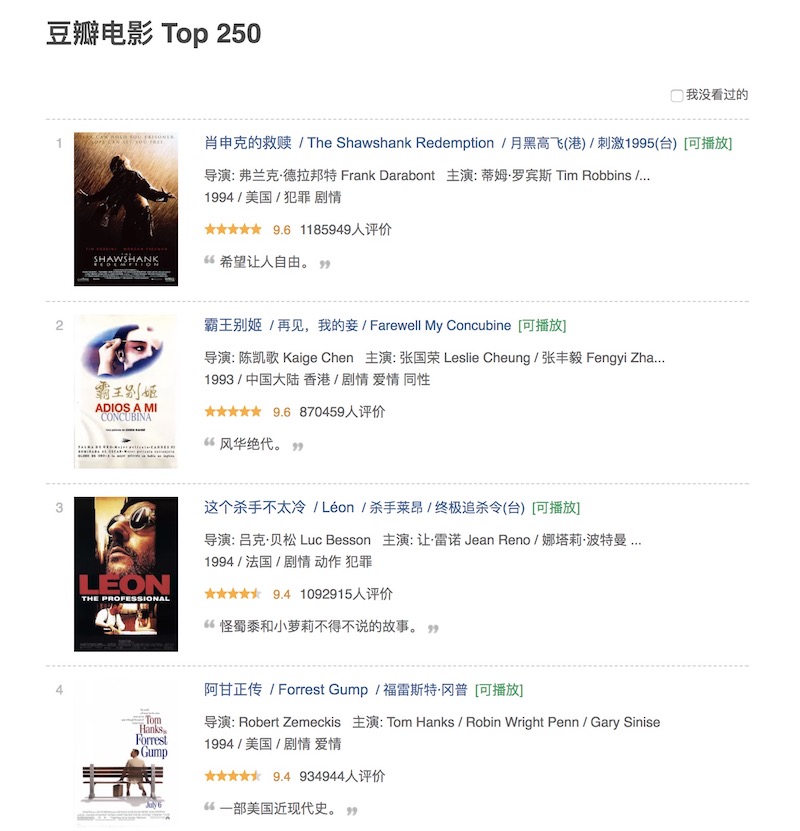
另外,在页面的下方,我们看到该榜单一共有10页的分页,点击第二页,可以看到URL变成了:https://movie.douban.com/top250?start=25&filter=,多了start=25&filter=的参数;点击第三页,此时URL变成了:https://movie.douban.com/top250?start=50&filter=。因此可以总结出,每页显示25部电影的信息,每页都在首页URL的基础上,增加了start参数的偏移量25。
另外,URL中的filter参数,如果勾选了“我没看过的”选项,那么该参数会变成filter=unwatched,页面只显示未看过的电影信息,不过该参数对于我们此次要爬取的内容没有影响。
爬取首页
首先,我们先获取该榜单第一页的内容:1
2
3
4
5
6
7
8
9
10
11
12
13def get_one_page(url):
headers = [
{'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0'},
{'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'},
{'User-Agent': 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11'},
{'User-Agent': 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)'},
{'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:40.0) Gecko/20100101 Firefox/40.0'},
{'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36'}
]
response = requests.get(url,headers=random.choice(headers))
if response.status_code == 200:
return response.text
return None
网站的反爬虫机制有很多,在这里,我们使用了User-Agent池。
运行代码,我们得到了该页的html,接下来就是解析该页面,用正则表达式提取我们想要的信息。
正则提取
分析html,可以发现每部电影信息都以如下的形式保存:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40<li>
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img width="100" alt="肖申克的救赎" src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.6</span>
<span property="v:best" content="10.0"></span>
<span>1185949人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
</li>
需要提取的信息以及对应的正则表达式如下:
1.影片排名1
pic".*?class="">(.*?)</em>
2.电影剧照1
pic".*?class="">(.*?)</em>.*?src="(.*?)"
3.电影名字1
pic".*?class="">(.*?)</em>.*?src="(.*?)".*?title">(.*?)</span>
4.电影评分1
pic".*?class="">(.*?)</em>.*?src="(.*?)".*?title">(.*?)</span>.*?average">(.*?)</span>
5.电影格言1
pic".*?class="">(.*?)</em>.*?src="(.*?)".*?title">(.*?)</span>.*?average">(.*?)</span>.*?inq">(.*?)</span>
列完正则表达式,接下来就是写一个提取函数,从刚才抓取的页面中提取出需要的信息:1
2
3
4
5
6
7
8
9
10
11
12def parse_one_page(html):
pattern = re.compile('pic".*?class="">(.*?)</em>.*?src="(.*?)".*?title">(.*?)</span>.*?average">(.*?)</span>.*?inq">(.*?)</span>',re.S)
items = re.findall(pattern,html)
#print(items)
for item in items:
yield {
'rank':item[0],
'pic':item[1],
'name':item[2],
'score':item[3],
'quote':item[4]
}
写入文件
将提取的内容写入文本文件中并保存下来:1
2
3def write_to_file(content):
with open('result.txt','a+',encoding='utf-8') as f:
f.write(str(content)+'\n')
分页爬取
完成了单页内容的爬取,现在要爬取整个完整榜单,只需要遍历一遍url链接,给url传入start参数,实现其余各个页面电影信息的爬取:1
2
3def write_to_file(content):
with open('result.txt','a+',encoding='utf-8') as f:
f.write(str(content)+'\n')
结果分析
另外,还可以利用urllib.request.urlretrieve方法下载并保存图片。
完整代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52import requests
import random
import re
import time
from urllib.request import urlretrieve
import os
def get_one_page(url):
headers = [
{'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0'},
{'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'},
{
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11'},
{'User-Agent': 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)'},
{'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:40.0) Gecko/20100101 Firefox/40.0'},
{
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36'}
]
response = requests.get(url,headers=random.choice(headers))
if response.status_code == 200:
return response.text
return None
def parse_one_page(html):
pattern = re.compile('pic".*?class="">(.*?)</em>.*?src="(.*?)".*?title">(.*?)</span>.*?average">(.*?)</span>.*?inq">(.*?)</span>',re.S)
items = re.findall(pattern,html)
#print(items)
for item in items:
yield {
'rank':item[0],
'pic':item[1],
'name':item[2],
'score':item[3],
'quote':item[4]
}
def write_to_file(content):
with open('result.txt','a+',encoding='utf-8') as f:
f.write(str(content)+'\n')
def main(start):
url = 'https://movie.douban.com/top250?start='+str(start)
html = get_one_page(url)
for item in parse_one_page(html):
write_to_file(item)
urlretrieve(item['pic'], filename='movie_pic'+os.sep+str(item['rank'])+'.jpg')
if __name__ == '__main__':
for i in range(10):
print(i)
main(start=i*25)
time.sleep(1)
得到的文本文件如图所示:
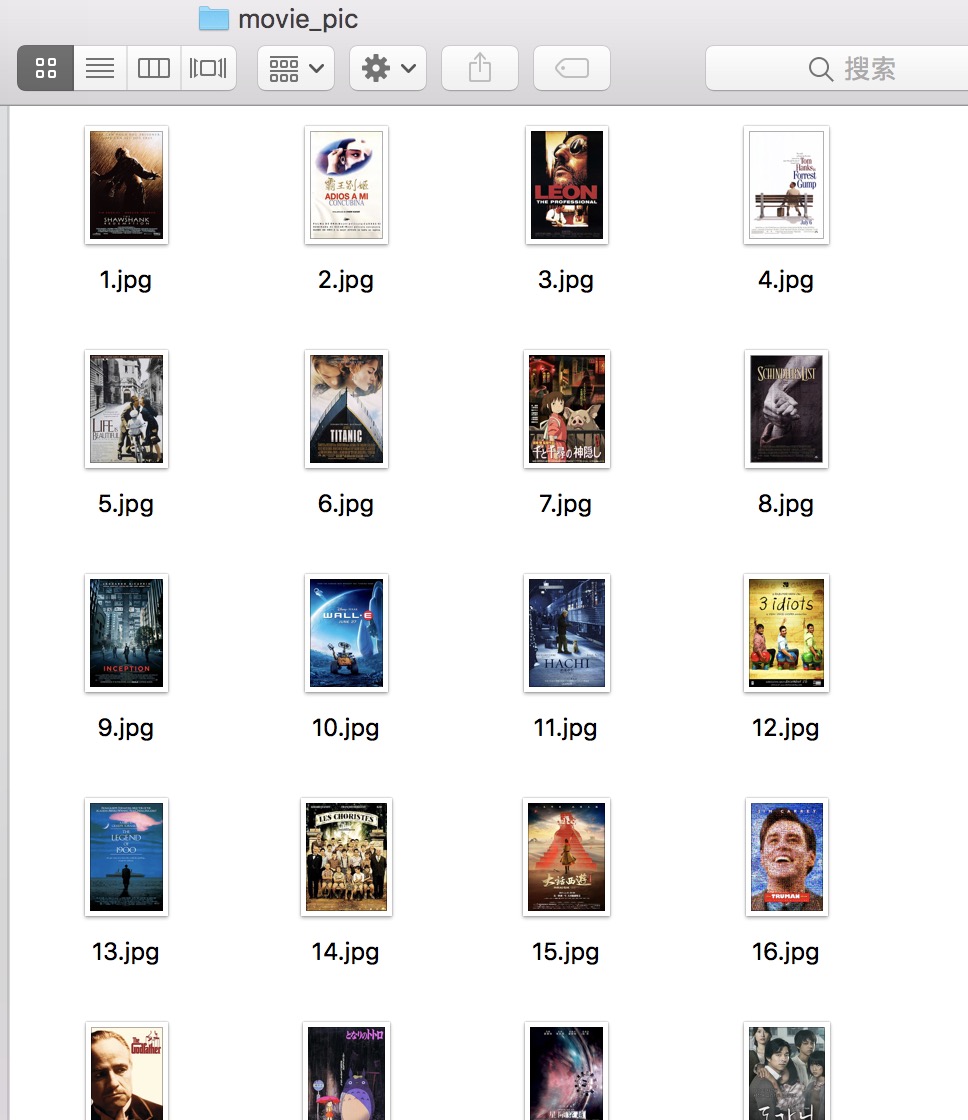
得到的影片图片如图所示: