目标分析
利用之前学习的requests库和正则表达式,我们来试着爬取猫眼电影Top100榜单的电影名称、时间、评分以及电影图片,并以文件形式保存爬取的结果。
我们的目标站点为:http://maoyan.com/board/4
下图就是我们可以查看到的榜单信息: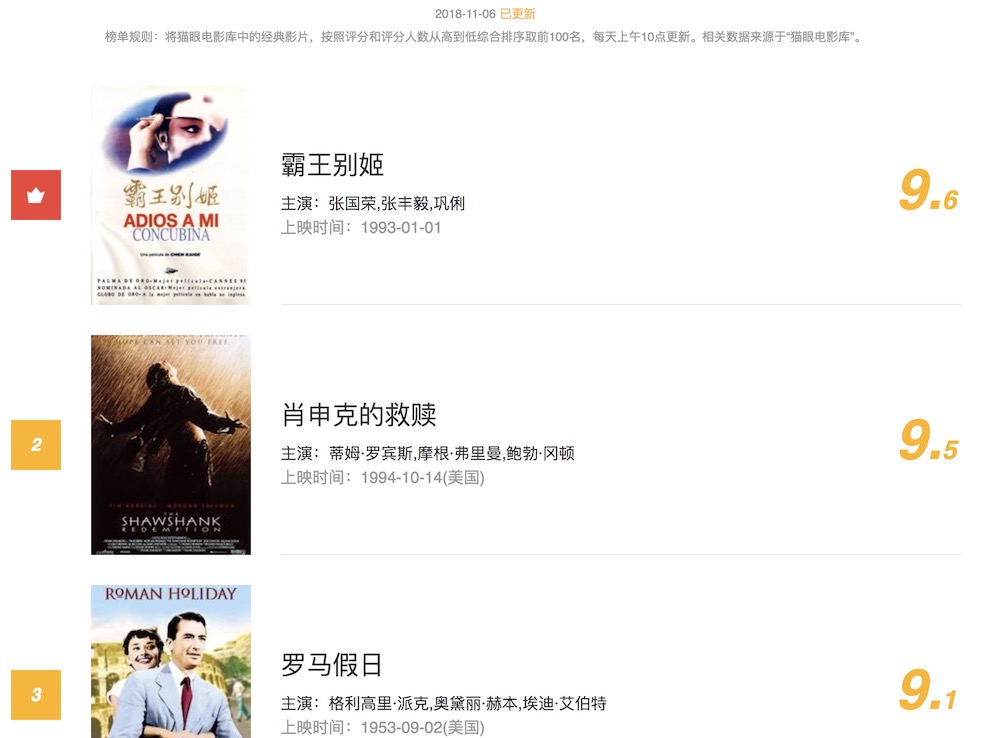
可以看到,排名第一的是《霸王别姬》,页面中还显示了主演、上映时间、上映地区、评分、剧照等信息。
另外,我们在首页的最下面还可以看到有分页列表,点击第二页,可以发现URL也发生了变化,变成了:http://maoyan.com/board/4?offset=10,这和之前相比,多了一个offset=10的参数,该页面显示的是排名11-20的电影;同样,我们点击第三页,URL变为:http://maoyan.com/board/4?offset=20,显示的是排名21-30的电影。所以,我们可以总结出每个分页的URl地址都是在首页的offset基础上再加10,第N页就是offset=10(N-1).
那么,为了获取Top100电影的信息,我们只要分开请求10次,设置不同的offset,在获取到的不同页面上,分别用正则表达式提取出想要爬取的信息即可。
爬取首页
首先我们要做的就是抓取第一页的内容1
2
3
4
5
6
7
8
9
10
11
12
13import requests
def get_one_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
print(html)
这样我们就得到了页面的源代码,接下来就要解析页面,提取我们想要的信息。
正则提取
1 | <dd> |
查看源代码,可以发现,每一部影片信息对应的都是一个
,用正则表达式从这一块中提取我们需要的信息。需要提取的信息以及对应的正则表达式如下:
1.影片排名
1 | <dd>.*?board-index.*?>(.*?)</i> |
2.电影图片
此时,正则表达式改写成:1
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)"
3.影片名称
此时,正则表达式改写成:1
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?<a.*?>(.*?)</a>
4.主演
此时,正则表达式改写成:1
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?<a.*?>(.*?)</a>.*?star.*?>(.*?)</p>
5.上映时间
此时,正则表达式改写成:1
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?<a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>
6.电影评分
此时,正则表达式改写成:1
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?<a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>
列完正则表达式,接下来要做的就是利用正则表达式在刚才的页面中提取我们想要获取的信息:1
2
3
4
5
6
7
8
9
10
11
12def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?<a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>',re.S)
items = re.findall(pattern,html)
for eachitem in items:
yield {
'rank':eachitem[0],
'image':eachitem[1],
'title':eachitem[2].strip(),
'actors':eachitem[3].strip(),
'realsetime':eachitem[4].strip(),
'score':eachitem[5].strip()+eachitem[6]
}
写入文件
这一步骤就是将爬取的内容写入到文本文件中。1
2
3def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
f.write(str(content)+'\n')
分页爬取
由于我们要爬取的是Top100的电影,所以还需要遍历一下,给url传入offset参数,实现其余各个页面电影信息的爬取。1
2
3
4
5
6
7for i in range(10):
url = 'http://maoyan.com/board/4?offset='+str(10*i)
html = get_one_page(url)
items = parse_one_page(html)
for each in items:
#print(each)
write_to_file(each)
结果分析
我们在代码里加入了延时等待,防止爬取速度过快而无响应。
完整代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35import requests
import re
import time
def get_one_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?<a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>',re.S)
items = re.findall(pattern,html)
for eachitem in items:
yield {
'rank':eachitem[0],
'image':eachitem[1],
'title':eachitem[2].strip(),
'actors':eachitem[3].strip(),
'realsetime':eachitem[4].strip(),
'score':eachitem[5].strip()+eachitem[6]
}
def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
f.write(str(content)+'\n')
for i in range(10):
url = 'http://maoyan.com/board/4?offset='+str(10*i)
time.sleep(1)
html = get_one_page(url)
items = parse_one_page(html)
for each in items:
write_to_file(each)
我们发现生成了一个叫作result.txt的文件,里面记录了Top100电影的信息,如下图所示: