第二章主要介绍了数据挖掘通用框架,方便后续的数据挖掘应用。
主要关注scikit-learn库。
估计器
scikit-learn库把一些相关功能封装成估计器,估计器用于分类任务,主要包括fit(),predict()两个函数。大部分scikit-learn估计器接收和输出的数据格式为numpy数组。
距离度量
最直观的就是欧式距离,其他常见的还有曼哈顿距离和余弦距离。
曼哈顿距离:两个特征在标准坐标系中绝对轴距之和。
余弦距离:适合解决异常值和数据稀疏问题,指特征向量夹角的余弦值。
选择哪种距离度量对最终结果影响很大。
这里主要引入的就是K近邻算法,因为很简单。
这里简单的介绍一下KNN:
首先计算测试数据与训练数据的距离,并按照距离的递增关系进行排序,选取距离最小的K个点,确定前K个点所在类别的概率,返回概率最高的类别作为该测试数据的预测分类。
电离层数据
这里主要引入电离层数据,如果一条数据能给出特殊结构存在的证据,该数据就认为是good,否则被分类为bad
step1:导入数据集
step2:将数据集分类测试集和训练集
step3:导入K近邻分类器,并初始化一个实例【暂时用默认参数,默认选择5个近邻作为分类依据】
step4:用训练集进行模型训练
strep5:用测试集进行测试,评估该模型的表现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import pandas as pd
data_path = 'Chapter 2/ionosphere.data'
datasets = pd.read_csv(data_path)
data = datasets.iloc[:,:34].values
target = datasets.iloc[:,34].values
from sklearn.model_selection import train_test_split
data_train,data_test,target_train,target_test = train_test_split(data,target,random_state=14)
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
estimator = KNeighborsClassifier() #初始化一个实例
estimator.fit(data_train,target_train)#训练模型
#测试集在该模型上的表现
predictor = estimator.predict(data_test)
accuracy = np.mean(predictor==target_test)*100
print("The accuracy is {0:.1f}%".format(accuracy))
#The accuracy is 84.1%
交叉验证
有时候由于测试集的关系,我们可能会误会某个算法表现不好,所以要进行交叉验证,解决这张一次性测试带来的问题。可以将数据多切分几次,保证每次切分的结果都不一样,并且确保每条数据只用来测试一次。
具体来说,就是将整个大的数据集分为几个部分,对于每个部分,划分为训练集和测试集,进行上例操作。最后将所有的accuracy取平均。【PS:每条数据只能在测试集中出现一次,以减少运气成分】
scikit-learn中就有交叉验证的函数1
2
3
4
5from sklearn.model_selection import cross_val_score
scores = cross_val_score(estimator,data,target,scoring='accuracy')
average_accuracy = np.mean(scores)*100
print("The average accuracy is {0:.1f}%".format(average_accuracy))
#The average accuracy is 82.3%
调参
通过上面的例子,我们可以看到采用默认配置,模型的准确度不是很高,所以要经过调参,来提高准确度。
调参是一门玄学
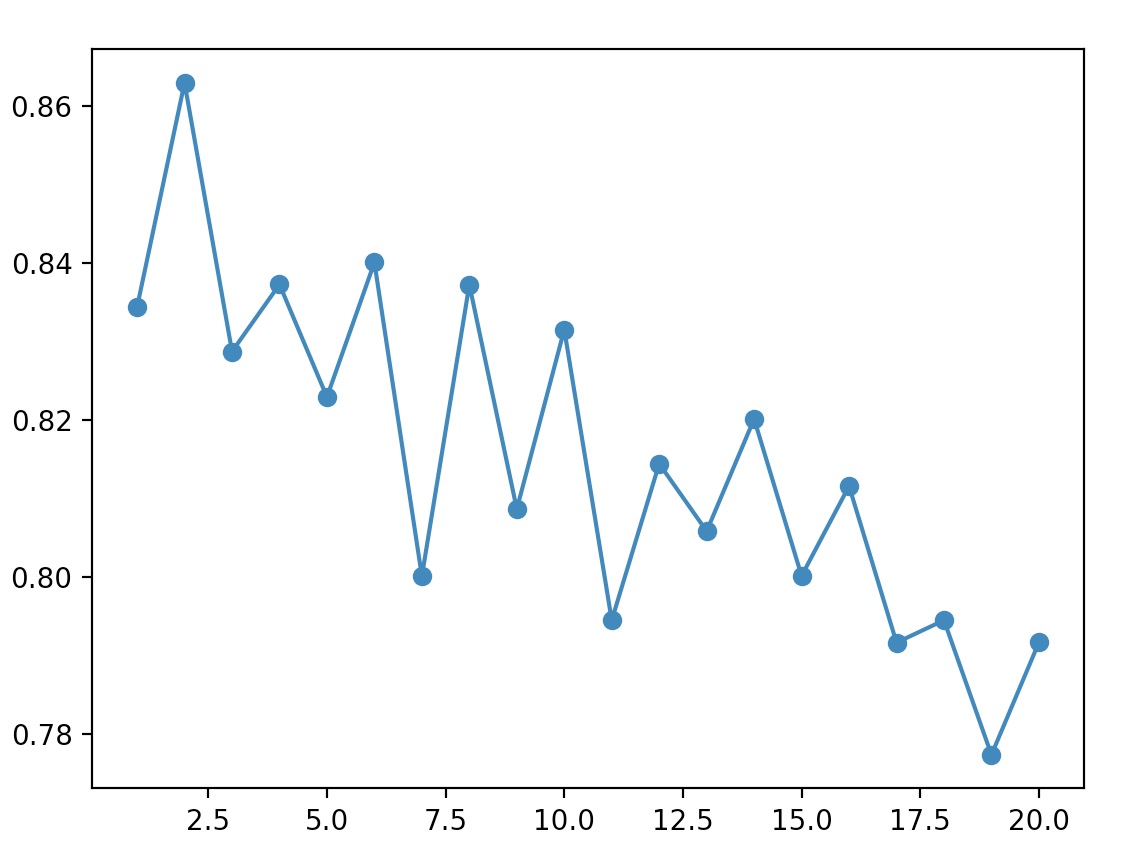
举例来说,KNN算法,K值过小,分类很容易受到干扰,随机性很强,K值过大,那么实际近邻的影响将削弱。
对于上述例子,我们将K值取1-20,分别计算其accuracy并比较。1
2
3
4
5
6
7
8
9
10avg_scores = []
k = [i for i in range(1,21)]
for n in range(1,21):
estimator = KNeighborsClassifier(n_neighbors=n)
scores = cross_val_score(estimator,data,target,scoring='accuracy')
avg_scores.append(np.mean(scores))
from matplotlib import pyplot as plt
plt.plot(k,avg_scores,'-o')
plt.show()
转换器
特征值的取值范围非常广,而特征值的大小实际上与分类效果没有任何关系,但是对于借助数学方法来比较特征的算法而言,取值大的特征可能比较显著,所以我们要对特征进行规范化。
scikit-learn又一个预处理工具叫做转换器(Transformer),接受原始数据集,返回转化后的数据集。转换器可以抽取特征,也可以处理数值型特征。
抽取特征:1
2
3from sklearn.feature_selection import VarianceThreshold
vt = VarianceThreshold()
Xt = vt.fit_transform(X)
处理数值型特征:
这里用MinMaxScaler类进行基于特征的规范化,这个类可以将特征值规范到01之间,最小值为0最大值为1,其余值在中间。
还有一些其他规范化处理的方法:
每条数据的特征值和为1:sklearn.preprocessing.Normalizer
各特征值均值为0,方差为1:sklearn.preprocessing.StandardScaler
数值型特征二值化:sklearn.preprocessing.Binarizer,大于阈值的为1,其余为01
2
3
4
5
6
7
8X_broken = np.array(data)
X_broken[:,::2] /= 10
from sklearn.preprocessing import MinMaxScaler
X_transformed = MinMaxScaler().fit_transform(X_broken)
estimator = KNeighborsClassifier()
transformed = cross_val_score(estimator,X_transformed,target,scoring='accuracy')
print('the average accuracy is {0:.1f}%'.format(np.mean(transformed)*100))
#the average accuracy is 82.3%
异常值会影响KNN,不同算法对值域大小的敏感度不同。
流水线
因为数据预处理的过程很多,为了方便代码的跟踪以及后续检查,用流水线结构将这些步骤保存到数据挖掘的工作流中。
流水线的输入为一连串的数据挖掘步骤,前面几步是转换器,最后一步必须是估计器estimator。数据由转换器进行处理,由估计器进行分类。
在上面这个例子中,流水线的结构大致就是:MinMaxScaler将特征取值规范到0-1 + 制定KNeighbourClassifier分类器。1
2
3from sklearn.pipeline import Pipeline
scaling_pipeline = Pipeline([('scale',MinMaxScaler()),
('predict',KNeighborsClassifier())])
流水线的核心是元素为元组的列表。第一个元组规范特征取值范围,第二个元组实现预测功能。’scale’和‘predict’的名字可以自己取,1
2
3
4
5from sklearn.pipeline import Pipeline
scaling_pipeline = Pipeline([('scale',MinMaxScaler()),('predict',KNeighborsClassifier())])
scores = cross_val_score(scaling_pipeline,X_broken,target,scoring='accuracy')
print('the pipeline scored an average accuracy is {0:.1f}%'.format(np.mean(scores)*100))
#the pipeline scored an average accuracy is 82.3%